6. 可信计算服务
6.1. 整体功能架构
可信计算服务是数据要素流通平台的核心服务之一,主要负责资源管理、任务管理、本地资源配置等功能。可信计算服务简称MIRA。
MIRA整体功能架构如下:
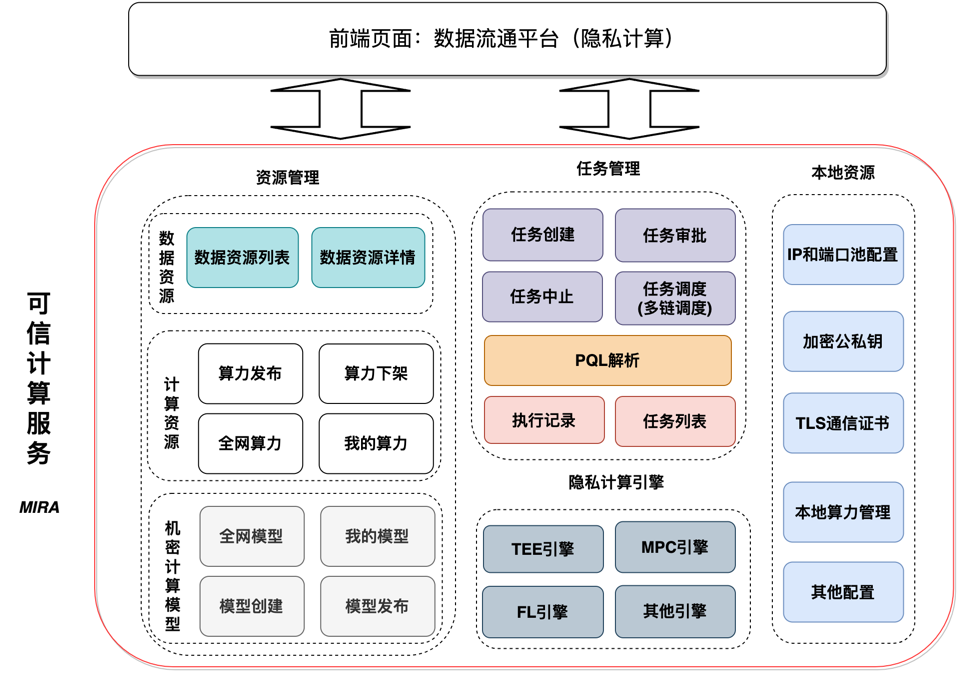
可信计算服务MIRA的整体功能包括以下几个模块:
资源管理: 数据资源管理、计算资源管理、机密计算模型管理
任务管理: 任务创建、任务审批、任务调度和执行,以及PQL解析和下载计算结果等
本地资源: ip和端口池、加密公私钥管理、TLS通讯证书、本地算力节点
隐私计算引擎: 主要包含TEE计算引擎、MPC计算引擎、FL计算引擎等
6.1.1. 资源管理
6.1.1.1. 数据资源管理
本模块提供了全网已登记上链的数据资源,包括数据资源的信息概要和详细信息的查询。
数据资源列表: 提供对数据资源的列表查询,包括数据资源的基本信息,包含数据产品编号、名称、登记时间等。
数据资源详情: 特定数据资源的详细信息,包括数据基本信息,数据集信息等。
6.1.1.2. 计算资源管理
本模块提供了全网已发布上链的计算资源信息查询,并支持发布本地的计算资源到全网。
计算资源列表: 提供对计算资源的列表查询,包括计算资源的基本信息,包含分组名称、链上交易ID、分组ID、当前状态等。
计算资源详情: 特定计算资源的详细信息,包括资源分组信息、算力板卡信息等。
计算资源发布: 允许用户发布本地的计算资源到全网,包括新增分组信息和算力板卡信息等。
计算资源上架: 允许用户将已发布的计算资源上架,使其可以被任务调度器选择并分配任务。
计算资源下架: 允许用户将已上架的计算资源下架,使其不再被任务调度器选择并分配任务。
6.1.1.3. 机密计算模型
本模块提供了全网已发布上链的机密计算模型的查询,并支持发布本地的机密计算模型到全网
机密计算模型列表: 提供对机密计算模型的列表查询,包括机密计算模型的基本信息,包含模型名称、类型、方法相关信息等。
机密计算模型详情: 特定机密计算模型的详细信息,包括模型的详细信息、模型的参数信息等。
机密计算模型发布: 允许用户发布本地的机密计算模型到全网,包括模型基本信息和模型使用信息等。
机密计算模型上架: 允许用户将已发布的机密计算模型上架,使其可以被任务调度器选择并分配任务。
机密计算模型下架: 允许用户将已上架的机密计算模型下架,使其不再被任务调度器选择并分配任务。
6.1.2. 计算任务
6.1.2.1. 任务管理
本模块提供了全网已发布上链的隐私计算任务信息查询,并支持创建隐私计算任务到全网。
任务创建: 允许用户创建隐私计算任务,指定隐私计算任务SQL,以及相关参数;
支持单次任务、流式任务、批次任务(支持设置执行次数)和周期处理(支持设置触发频率)多种处理方式;
支持任务手动触发执行或自动触发执行任务;
任务列表: 提供对隐私计算任务的列表查询,包括任务的基本信息,包含任务名称、任务类型、任务状态等信息。
任务详情: 特定隐私计算任务的详细信息,包括任务的基本信息、数据产品、算法模型、任务执行示意图、子任务信息等。
任务中止: 允许用户中止执行中的隐私计算任务(当前仅支持流式任务的中止),中止任务后,任务执行器会停止任务的执行。
任务执行记录: 提供对隐私计算任务的执行记录查询,包括任务的执行记录次数的统计,执行状态、任务执行结果下载等信息。
6.1.2.2. 任务审批
本模块提供了全网已发布上链的隐私计算任务审批信息查询,并支持审批本组织参与的隐私计算任务。
任务审批: 允许用户对自己参与的隐私计算任务进行审批,包括填写审批结果、审批意见等。当审批流式任务时,允许审批人员额外填写或完善流式服务配置信息。
任务审批列表: 提供对隐私计算任务的审批列表查询,包括任务的基本信息,包含任务名称、任务类型、任务状态等信息。
任务审批详情: 特定隐私计算任务的审批详细信息,包括审批信息的统计,任务的基本信息、数据产品、算法模型、任务执行示意图、子任务信息等。
6.1.2.3. 任务调度和执行
隐私计算任务审批通过后,调度服务会自动调度审批通过的任务。 调度服务整体架构如下:
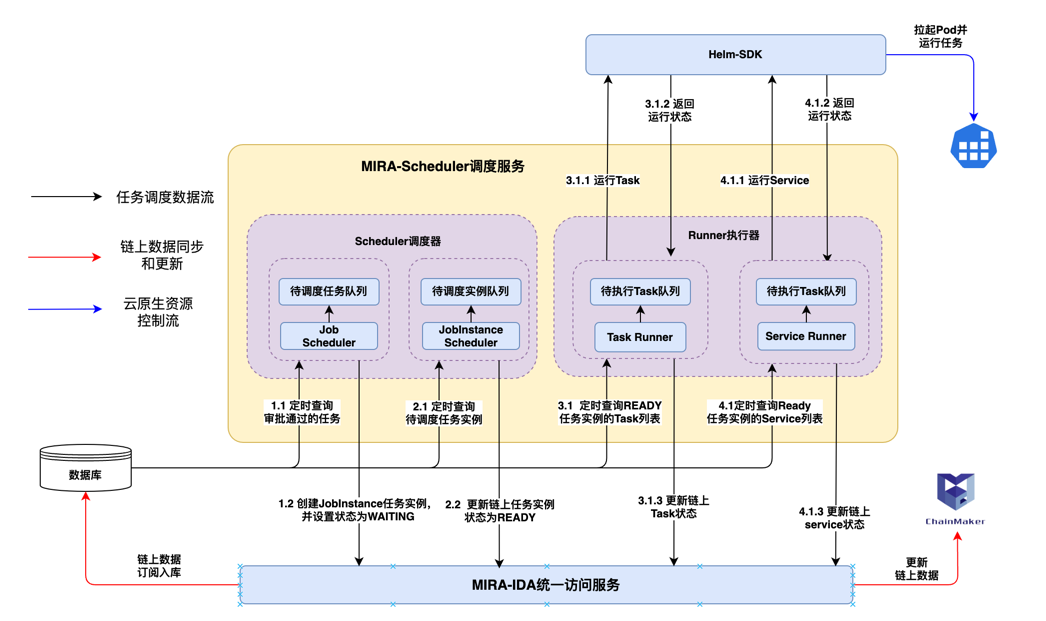
任务调度关键流程:
任务审批:任务创建后,数据资源提供方会对任务进行审批,审批通过后任务会进入调度队列。
任务调度:任务调度器会根据任务的优先级、资源的可用性等因素进行任务调度,选择合适的资源进行任务执行。
任务执行:任务执行器会根据任务的执行计划,执行任务,生成任务执行结果。
任务结果:任务执行完成后,任务执行器会将任务执行结果存储到对象存储中,供结果使用方下载查看。
调度服务关键组件和功能:任务调度服务主要包含调度器和执行器,功能如下:
Scheduler调度器:定时遍历审批成功的Job任务并根据处理类型生成对应的JobInstance任务实例
Job Scheduler
jobSynchronizer定时查询审批通过的Job任务,并放入待调度任务队列
根据不同处理类型的Job构造任务实例JobInstance
如果任务是加密任务,则调用加密服务生成加密任务实例
更新JobInstance到链上
JobInstance Scheduler
jobInstanceSynchronizer定时查询审批通过的Job任务定时查询待执行的JobInstance任务实例,并放入待执行任务队列
更新JobInstance任务实例状态,并更新到链上,通知其他参与方
Runner执行器: 遍历待执行的JobInstance任务实例,并获取对应的子任务Task或Service,通过helm在k8s集群中创建对应的资源,并执行任务
taskRunner:
taskSynchronizer定时查询待执行的Task列表,并放入待执行Task队列
处理不同状态的task,如:创建k8s资源并执行任务
更新task状态,并更新到链上
serviceRunner:
serviceSynchronizer定时查询待执行的Service列表,并放入待执行Service队列
处理不同状态的service,如:创建k8s资源并执行任务
更新service状态,并更新到链上
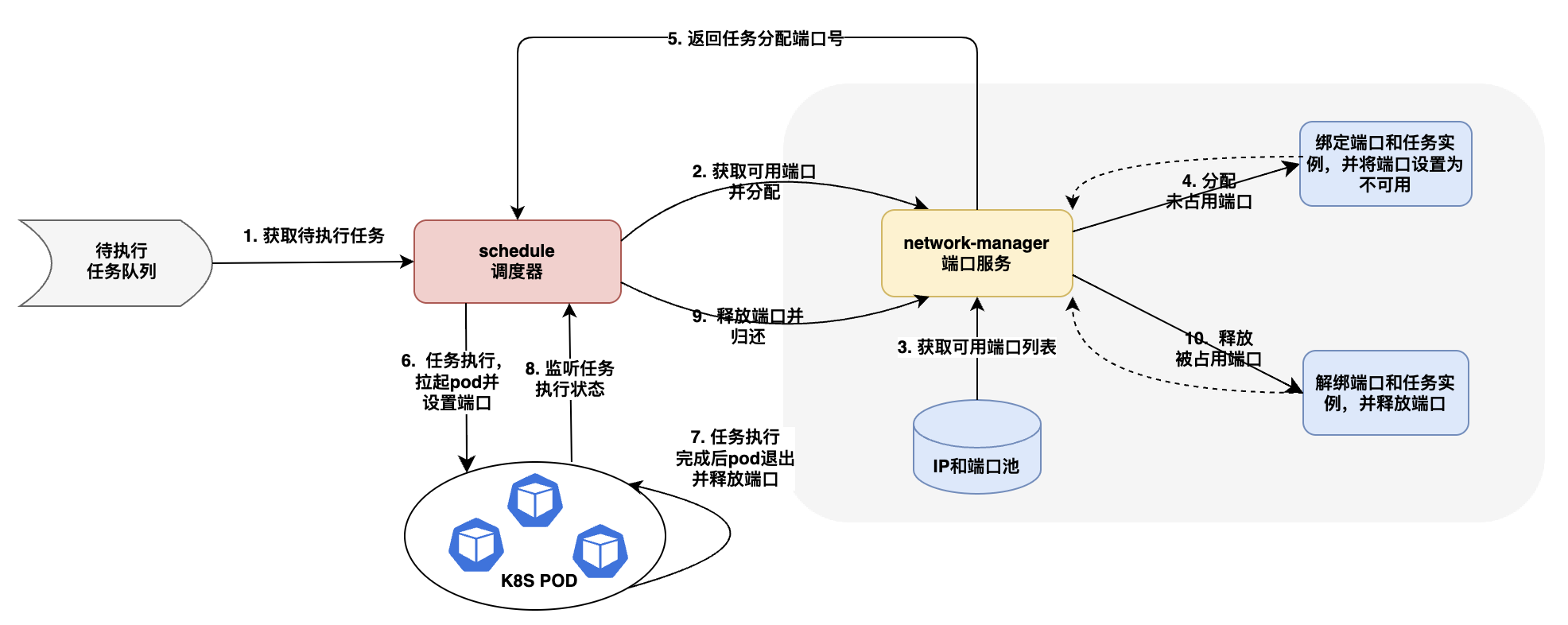
端口管理服务
端口管理服务为在scheduler中收到的任务分配k8s执行端口,需要在端口池配置中指定端口范围是30000-32767中的一个端口段。如果用户创建的是单次任务、批次任务或者周期任务,则调度不会指定固定的端口号,随机为任务从端口池中分配一个端口,如果是流式任务,则申请一个指定的端口。schedule调度服务会一直监听任务使用情况,如果任务执行完成,则调用端口服务更新端口使用状态,释放端口。 对于单次、批次和周期任务,具体的端口调度流程如下图所示:
6.1.3. 本地资源
6.1.3.1. IP和端口池配置
本模块提供了管理本地平台对外使用的IP和端口池信息功能。在部署MIRA服务后,需要首先配置IP和端口池信息,以便端口管理服务为任务分配端口。
IP和端口池配置: 允许管理员配置服务所使用的 IP 地址和端口范围。
IP和端口池列表: 提供对IP和端口池的列表查询。
6.1.3.2. 加解密的公私钥配置
本模块提供了管理本地平台结果加密和解密过程中使用的公钥和私钥信息功能。在任务创建时,用户可以选择使用特定的公私钥对计算结果进行加密和解密。
加解密的公私钥新增: 允许管理员新增公钥和私钥,并且指定公私钥的名称和描述。
加解密的公私钥列表: 提供对加解密的公私钥的列表查询。
加解密的公私钥详情: 显示特定加解密的公私钥的详细信息。
加解密的公私钥删除: 允许管理员删除特定的公私钥。
加解密的公私钥更新: 允许管理员更新特定的公私钥。
6.1.3.3. TLS通讯证书配置
本模块提供了管理本地平台的TLS通讯证书信息功能。在创建”流式任务“时,用户可以选择使用特定的TLS通讯证书对通讯数据进行加密。
TLS 通讯证书新增: 允许管理员新增TLS通讯证书,包含CA证书(可选)、TLS证书、TLS私钥,并且指定证书的名称和描述。
TLS 通讯证书列表: 提供对TLS通讯证书的列表查询。
TLS 通讯证书详情: 显示特定TLS通讯证书的详细信息。
TLS 通讯证书删除: 允许管理员删除特定的TLS通讯证书。
TLS 通讯证书更新: 允许管理员更新特定的TLS通讯证书。
6.1.3.4. 本地算力节点配置
本模块提供了管理本地平台的算力节点信息功能。用于录入本地板卡信息,以便于资源管理-计算资源管理中发布本地算力节点到全网。
本地算力节点新增: 允许管理员新增本地算力节点,包含节点名称、节点地址、节点规格,板卡等信息。
本地算力节点列表: 提供对本地算力节点的列表查询。
本地算力节点详情: 显示特定本地算力节点的详细信息。
本地算力节点删除: 允许管理员删除特定的名称的本地算力节点。
本地算力节点更新: 允许管理员更新特定的本地算力节点。
以上功能模块组成了MIRA管理服务的核心功能,用户可以通过界面操作实现相关的管理和控制操作。
6.2. 统一访问服务
统一访问服务:对应微服务 mira-ida-access-service,简称 mias,是数据要素流通平台的核心服务之一,主要负责可信计算服务与
IDA数据产品登记服务和public公共服务的交互,并为可信计算服务提供数据产品访问以及链访问的统一能力。
6.2.1. 整体架构
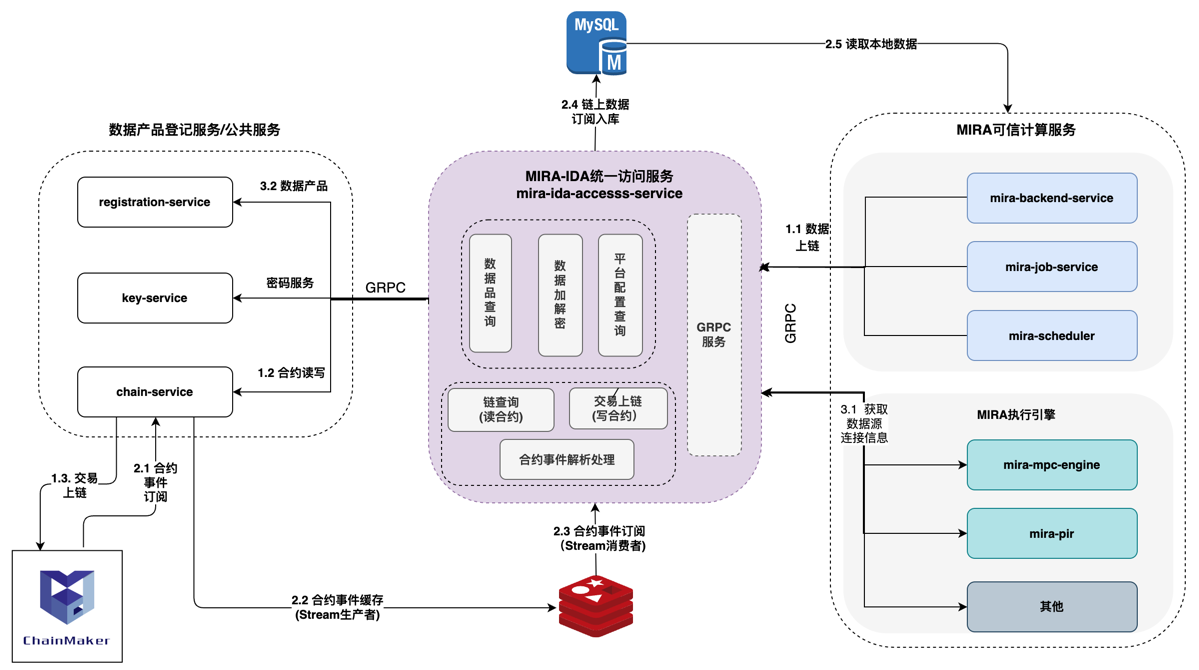
统一访问服务主要包括以下几个模块:
数据产品查询:通过调用
registraction-service数据登记服务,实现全网数据产品列表查询、数据产品详情查询、数据产品对应本地数据源连接信息查询等功能。平台配置查询:提供平台配置信息查询功能,如:平台ID、平台公钥(用于链上数据加密)、平台名称等,其中平台ID用于标识平台的唯一性,并用于对数据进行过滤。
数据加解密:通过调用
key-service实现数据加解密功能链查询:通过调用
chain-service实现链上数据读取交易上链:通过调用
chain-service实现交易上链功能合约事件解析处理:订阅redis中的链上合约事件,解析通过后写入本地数据库,供后续MIRA可信计算服务查询使用
GRPC服务:提供GRPC服务,供其他服务调用
数据上链流程
1.1 数据上链:MIRA可信计算服务调用统一访问服务进行数据上链,如任务信息上链;统一访问服务通过调用交易上链接口,并将请求转发给链服务,进行合约读写操作
1.2 合约读写:链服务
chain-service接收到请求后,使用key-service对请求进行签名,然后使用链SDK将交易发送给ChainMaker长安链服务
数据订阅流程
2.1 合约事件订阅:链服务
chain-service订阅链上合约事件,并对合约事件状态进行检查2.2 合约事件缓存:当合约事件为成功时,链服务
chain-service将合约事件写入redis缓存2.3 合约事件订阅处理:统一访问服务
mias订阅redis中的链上合约事件,解析通过后写入本地数据库,供后续MIRA可信计算服务查询使用
数据查询流程(以执行引擎查询为例):
3.1 获取数据源连接信息:执行引擎在执行时需要通过统一访问服务获取数据源连接信息,通过调用数据源连接信息接口,获取数据源连接信息。
3.2 数据产品查询:统一访问服务调用
registraction-service数据登记服务,获取数据产品对应本地数据源连接信息。
6.2.2. GRPC关键接口
统一访问服务提供了一系列GRPC接口,供其他服务调用,如:数字资产的查询,平台信息的查询,区块链的读写操作,智能合约的事件订阅等。
6.2.2.1. 合约调用
//通用接口
rpc CallContract(CallContractRequest) returns(ContractResponse) {};
//创建job
rpc CreateJob(ContractRequest) returns(ContractResponse) {};
//创建job审批
rpc CreateJobApprove(ContractRequest) returns(ContractResponse) {};
...
6.2.2.2. 平台配置查询
// 平台配置
rpc GetPlatformInfo(GetPlatformInfoRequest)returns(PlatformDataResponse);
// 多链配置
rpc ListChainInfo(ListChainInfoRequest) returns(ListChainInfoResponse) {};
6.2.2.3. 数据产品查询
// 1. 获取包含隐私信息的数据源连接信息接口
rpc GetPrivateDBConnInfo(GetPrivateDBConnInfoReq) returns (GetPrivateDBConnInfoResp);
// 2. 获取链上资产列表
rpc GetPrivateAssetList(GetPrivateAssetListReq) returns (GetPrivateAssetListResp);
// 3. 获取链上资产详情
rpc GetPrivateAssetInfo(GetPrivateAssetInfoReq) returns (GetPrivateAssetInfoResp);
...
6.2.2.4. 数据加解密
// 生成密钥
rpc CreateKey(KeyCreateRequest) returns(KeyCreateResponse);
// 加密
rpc Encrypt(KeyEncryptRequest) returns(KeyEncryptResponse);
// 解密
rpc Decrypt(KeyDecryptRequest) returns(KeyDecryptResponse);
// 数字信封加密
rpc EncWithDeK(DataEnvelopeEncryptRequest) returns(DataEnvelopeEncryptResponse);
// 数字信封解密
rpc DecByKeK(DataEnvelopeDecryptRequest) returns(KeyDecryptResponse);
...
6.3. PQL解析引擎
PQL:隐私查询语言(Privacy Query Language),是一种用于隐私计算的查询语言,支持多方计算、隐私求交、机密计算等多种计算任务。
PQL解析引擎是MIRA可信计算服务的核心模块之一,用于完成用户需求到执行任务的转换与编排功能,PQL解析功能由 mira-job-service服务提供。
用户通过PQL发起计算任务后,解析模块根据语法文件对SQL语句进行解析,并与链上数据目录进行校验后生成执行计划,通过优化器完成规则优化与代价优化,生成执行任务。
6.3.1. 整体架构
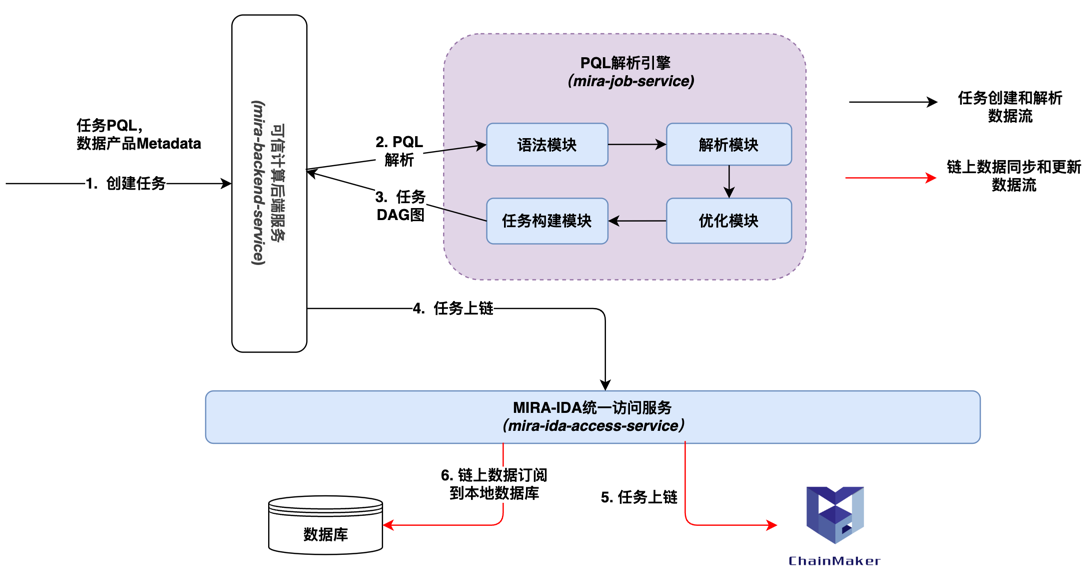
PQL解析引擎主要分为以下模块
语法模块:定义了PQL支持的所有词法和语法,可以将PQL语句转换为抽象语法书,并提供遍历方法。
解析模块:主要支持将语法树按照执行逻辑转换为PQL的逻辑计划树,每个树节点对应的是一个逻辑执行任务。
优化模块:提供针对逻辑计划树的规则优化和代价优化,生成实际的执行计划。
任务构建模块:提供任务执行图DAG的生成,将执行计划节点转换为对应的任务算子。
关键流程:
创建任务:用户通过前端界面创建任务,包含:任务PQl和数据产品Metadata2.
PQL解析:可信计算后端服务调用PQL解析引擎,解析SQL语句,生成任务执行图DAG
任务DAG图:PQL解析引擎对用于SQL语句,进行语法分析、解析优化、并进行任务构建,生成任务DAG图
任务上链:可信计算后端服务将任务信息通过统一访问服务进行上链。
链上数据订阅:相关参与方通过订阅链上数据,获取任务DAG图,并存储在本地数据库,等待审批和调度
6.3.2. PQL语法
PQL按照支持的隐私计算类型分为:联邦计算、机密计算、联邦学习; 按照计算场景分为:隐私求交、匿名查询、联合统计、联合计算(评分卡)等。
可信计算服务PQL语法当前支持的隐私计算类型包含:
联邦计算
机密计算(支持PQL和算子,当前版本不开源)
联邦学习(仅支持PQL,执行算子当前版本未支持)
可信计算服务PQL语法当前支持的隐私计算场景主要为:
隐私求交
匿名查询
联合统计
联合计算(评分卡)
下面举例介绍联邦计算PQL语法,以使用两方数据为例:
ATEST和BTEST表示数据产品英文名称,分别来自参与方A和参与方BATEST和BTEST数据产品对应的数据表结构如下
ATEST(ID INT, A1 INT, A2 INT)
BTEST(ID INT, B1 INT, B2 INT)
TEE为机密计算关键词
常用PQL示例如下:
| 场景 \ 隐私计算类型 | MPC写法 | TEE写法 |
|---|---|---|
| 隐私求交 | SELECT ATEST.ID FROM ATEST, BTEST WHERE ATEST.ID=BTEST.ID |
SELECT /*+ JOIN(TEE) */ ATEST.ID FROM ATEST, BTEST WHERE ATEST.ID=BTEST.ID |
| 匿名查询 | SELECT ATEST.K FROM ATEST WHERE ATEST.ID=? |
SELECT /*+ FILTER(TEE) */ ATEST.K FROM ATEST WHERE ATEST.ID=? |
| 联合统计 | 1)SELECT ATEST.K * BTEST.K FROM ATEST, BTEST WHERE ATEST.ID=BTEST.ID</br> 2) SELECT SUM(ATEST.K * BTEST.K) FROM ATEST, BTEST WHERE ATEST.ID=BTEST.ID</br> 3) SELECT AVG(ATEST.K * BTEST.K) FROM ATEST, BTEST WHERE ATEST.ID=BTEST.ID</br> 4) SELECT MAX(ATEST.K * BTEST.K) FROM ATEST, BTEST WHERE ATEST.ID=BTEST.ID</br> 5) SELECT MIN(ATEST.K * BTEST.K) FROM ATEST, BTEST WHERE ATEST.ID=BTEST.ID</br> 6) SELECT COUNT(ATEST.ID) FROM ATEST, BTEST WHERE ATEST.ID=BTEST.ID |
1)SELECT /*+ FUNC(TEE) */ MUL(ATEST.K,BTEST.K) FROM ATEST, BTEST WHERE ATEST.ID=BTEST.ID</br> 2) SELECT /*+ FUNC(TEE) */ MULSUM(ATEST.K,BTEST.K) FROM ATEST, BTEST WHERE ATEST.ID=BTEST.ID</br> 3) SELECT /*+ FUNC(TEE) */ MULAVG(ATEST.K,BTEST.K) FROM ATEST, BTEST WHERE ATEST.ID=BTEST.ID</br> 4) SELECT /*+ FUNC(TEE) */ MULMAX(ATEST.K,BTEST.K) FROM ATEST, BTEST WHERE ATEST.ID=BTEST.ID</br> 5) SELECT /*+ FUNC(TEE) */ MULMIN(ATEST.K,BTEST.K) FROM ATEST, BTEST WHERE ATEST.ID=BTEST.ID</br> 6) SELECT /*+ FUNC(TEE) */ COUNT(ATEST.ID) FROM ATEST, BTEST WHERE ATEST.ID=BTEST.ID |
| 联合计算(评分卡) | SELECT ID, (0.1 * ATEST.A1) + (0.2 * BTEST.B1) FROM ATEST JOIN BTEST WHERE ATEST.ID=BTEST.ID |
SELECT ID, /*+FUNC(TEE)*/ SCORE(0.1, ATEST.A1, 0.2, BTEST.B2, 0.1) FROM ATEST JOIN BTEST WHERE ATEST.ID=BTEST.ID |
常用PQL子查询示例如下:
# 子查询分组别名1
select
ATEST.A1,
tmp_table.ID
from
ATEST,
BTEST,
(
select
tmp_inner.ID,
tmp_inner.cnt,
tmp_inner.tot_val
from
(
select
ATEST.ID,
count(ATEST.A1) as cnt,
sum(ATEST.A1) as tot_val
from
ATEST
group by ATEST.ID
) tmp_inner
) tmp_table
where
ATEST.ID= BTEST.ID
and
tmp_table.ID= BTEST.ID
6.3.3. PQL任务结构
PQL解析引擎会将PQL语句解析为任务结构,任务结构包含Job和Task两个部分,Job为任务的基本信息,Task为任务的执行信息。
Job数据结构
{
"jobID": string, ## Job ID
"jobName": string, ## Job名称
"jobType": string, ## Job类型 //FQS(联邦查询)、FL(联邦学习)
"status": string, ## Job状态 WAITING/APPROVED/READY/RUNNING/CANCELED/FAILED/SUCCESS
"submitter": string, ## Job提交者ID
"updateTime": string, ## 状态变更时间戳
"createTime": string, ## 创建日期时间戳
"requestData": string, ## 请求数据原文
"tasksDAG": string, ## 根据原文生成的task的DAG
"parties": []string, ## 参与方ID数组
}
Task数据结构
{
"version": string, ##Task格式版本
"jobID": string, ## Job ID
"taskName": string, ## Task名称
"status": string, ## Task状态 WAITING/INIT/SETUP/READY/RUNNING/CANCELED/FAILED/SUCCESS
"updateTime": string, ## 变更时间戳
"createTime": string, ## 创建日期时间戳
"module": { ## Task模块
"moduleName": string, ## 模块名称 MPC(多方计算)/PSI(隐私求交)/TEE(机密计算)/TEEPSI(硬件隐私求交)
"params":{ ## 模块参数
"param1": string, ## 参数1
"param2": string, ## 参数2
...
},
},
"input": { ## 输入
"data":[ ## 数据
{
"dataName": string, ## 数据名称
"taskSrc": string, ## 数据来源taskName(如果数据不是由当前job内部产生,则为空)
"dataID": string, ## 数据ID(如果数据不是由当前job内部产生,此字段不为空)
"domainID": string, ## 数据提供者ID(如果数据不是由当前job内部产生,此字段不为空)
"role": string, ## GUEST/HOST
"params":{ ## 数据参数
"param1": string, ## 参数1
"param2": string, ## 参数2
...
},
},
...
],
},
"output": { ## 输出
"data":[ ## 数据
{
"dataName": string, ## 数据名称
"finalResult": string, ## Y/N/YE
"domainID": string, ## 数据提供者ID
"dataID": string, ## 数据ID(由数据提供者选择填写,便于追溯)
},
...
],
},
"parties":[
{
"partyID": string, ## 参与方ID,对应input data中的domainID
"serverInfo":{ ## 参与方服务信息,由参与方填写
"ip": string, ## ip地址
"port": string, ## 端口
...
},
"status": string, ## 参与方服务任务状态
## INIT/SETUP/READY/RUNNING/CANCELED/FAILED/SUCCESS
"timestamp": string, ## 变更时间戳
},
...
]
}
6.3.4. PQL解析示例
6.3.4.1. 过滤
支持”>”、”<”、”=”、”>=”、”<=”
SELECT TEST_B_1.ID FROM TEST_B_1 WHERE TEST_B_1.B1>5
任务结构
"module": {
"moduleName": "LOCALFILTER",
"params": {
"operator": ">",
"constant": 5
}
},
"input": {
"data":[
{
"dataName": "TEST_B_1",
"taskSrc": "",
"dataID": "TEST_B_1",
"domainID": "wx-org2.chainmaker.org",
"role": "",
"params":{
"table":"TEST_B_1",
"field": "B1"
},
},
],
},
6.3.4.2. 求交
支持”=”,默认Inner Join类型
SELECT TEST_B_1.ID FROM TEST_B_1,TEST_C_1 WHERE TEST_B_1.ID=TEST_C_1.ID
任务结构
"module": {
"moduleName": "OTPSI",
"params": {
"joinType": "INNER",
"operator": "="
}
},
"input": {
"data": [
{
"dataName": "TEST_B_1",
"taskSrc": "",
"dataID": "TEST_B_1",
"domainID": "wx-org2.chainmaker.orgId",
"role": "client",
"params": {
"table": "TEST_B_1",
"field": "ID"
}
},
{
"dataName": "TEST_C_1",
"taskSrc": "",
"dataID": "TEST_C_1",
"domainID": "wx-org3.chainmaker.orgId",
"role": "server",
"params": {
"table": "TEST_C_1",
"field": "ID"
}
}
]
},
SELECT /*+ JOIN(TEE) */ TEST_B_1.ID FROM TEST_B_1,TEST_C_1 WHERE TEST_B_1.ID=TEST_C_1.ID
任务结构
"module": {
"moduleName": "TEEPSI",
"params": {
"joinType": "INNER",
"operator": "=",
"teeHost": "192.168.40.230",
"teePort": "30091",
"domainID": ""
}
},
"input": {
"data": [
{
"dataName": "TEST_B_1",
"taskSrc": "",
"dataID": "TEST_B_1",
"domainID": "wx-org2.chainmaker.orgId",
"role": "client",
"params": {
"table": "TEST_B_1",
"field": "ID"
}
},
{
"dataName": "TEST_C_1",
"taskSrc": "",
"dataID": "TEST_C_1",
"domainID": "wx-org3.chainmaker.orgId",
"role": "server",
"params": {
"table": "TEST_C_1",
"field": "ID"
}
}
]
},
6.3.4.3. 计算
支持”+”、”-”、”*”、”/”
SELECT TEST_B_1.B1+TEST_C_1.C1-TEST_C_1.C2 FROM TEST_B_1,TEST_C_1 WHERE TEST_B_1.ID=TEST_C_1.ID
任务结构
"module": {
"moduleName": "MPCEXP",
"params": {
"function": "base",
"expression": "x+x-x"
}
},
"input": {
"data": [
{
"dataName": "wx-org2.chainmaker.orgId-1",
"taskSrc": "0",
"dataID": "",
"domainID": "wx-org2.chainmaker.orgId",
"role": "server",
"params": {
"table": "TEST_B_1",
"field": "B1",
"type": "3",
"index": "[0]"
}
},
{
"dataName": "wx-org3.chainmaker.orgId-1",
"taskSrc": "0",
"dataID": "",
"domainID": "wx-org3.chainmaker.orgId",
"role": "client",
"params": {
"table": "TEST_C_1",
"field": "C1",
"type": "3",
"index": "[1]"
}
},
{
"dataName": "wx-org3.chainmaker.orgId-1",
"taskSrc": "0",
"dataID": "",
"domainID": "wx-org3.chainmaker.orgId",
"role": "client",
"params": {
"table": "TEST_C_1",
"field": "C2",
"type": "3",
"index": "[2]"
}
}
]
},
6.3.4.4. 聚合
支持SUM、COUNT、AVG、MAX、MIN
SELECT SUM(TEST_B_1.B1+TEST_C_1.C1) FROM TEST_B_1,TEST_C_1 WHERE TEST_B_1.ID=TEST_C_1.ID
任务结构
"module": {
"moduleName": "MPC",
"params": {
"function": "SUM",
"expression": "x+x"
}
},
"input": {
"data": [
{
"dataName": "wx-org2.chainmaker.orgId-1",
"taskSrc": "0",
"dataID": "",
"domainID": "wx-org2.chainmaker.orgId",
"role": "server",
"params": {
"table": "TEST_B_1",
"field": "B1",
"type": "3",
"index": "[0]"
}
},
{
"dataName": "wx-org3.chainmaker.orgId-1",
"taskSrc": "0",
"dataID": "",
"domainID": "wx-org3.chainmaker.orgId",
"role": "client",
"params": {
"table": "TEST_C_1",
"field": "C1",
"type": "3",
"index": "[1]"
}
}
]
},
6.3.4.5. 联邦学习
支持HESB、HOSB、HELR、HEKMS、HELNR、HOLR、HEPR、HEFTL、HENN、HONN
SELECT
FL(
is_train = true,
is_test = false,
FLLABEL(
SOURCE_DATA = BREAST_HETERO_GGUEST,
with_label = true, label_type = int,
output_format = dense, namespace = experiment
),
FLLABEL(
SOURCE_DATA = BREAST_HETERO_HHOST,
with_label = false, output_format = dense,
namespace = experiment
),
INTERSECTION(
intersect_method = rsa
),
HELR(
penalty = L2, tol = 0.0001, alpha = 0.01,
optimizer = rmsprop, batch_size =-1,
learning_rate = 0.15, init_param.init_method = zeros,
init_param.fit_intercept = true,
max_iter = 15, early_stop = diff, encrypt_param.key_length = 1024,
reveal_strategy = respectively, reveal_every_iter = true
),
EVAL(eval_type = binary)
)
FROM
BREAST_HETERO_GGUEST,
BREAST_HETERO_HHOST
任务结构
"module": {
"moduleName": "FL",
"params": {
"intersection": {
"intersect_method": "rsa"
},
"fl": {
"is_test": "false",
"is_train": "true"
},
"model": {
"batch_size": "-1",
"penalty": "L2",
"early_stop": "diff",
"reveal_strategy": "respectively",
"tol": "0.0001",
"model_name": "HELR",
"optimizer": "rmsprop",
"alpha": "0.01",
"init_param": {
"init_method": "zeros",
"fit_intercept": "true"
},
"encrypt_param": {
"key_length": "1024"
},
"reveal_every_iter": "true",
"learning_rate": "0.15",
"max_iter": "15"
},
"eval": {
"eval_type": "binary"
}
}
},
"input": {
"data": [
{
"dataName": "BREAST_HETERO_GGUEST",
"taskSrc": "",
"dataID": "BREAST_HETERO_GGUEST",
"domainID": "wx-org2.chainmaker.orgId",
"role": "guest",
"params": {
"output_format": "dense",
"namespace": "experiment",
"with_label": "true",
"label_type": "int",
"table": "BREAST_HETERO_GGUEST"
}
},
{
"dataName": "BREAST_HETERO_HHOST",
"taskSrc": "",
"dataID": "BREAST_HETERO_HHOST",
"domainID": "wx-org3.chainmaker.orgId",
"role": "host",
"params": {
"output_format": "dense",
"namespace": "experiment",
"with_label": "false",
"label_type": null,
"table": "BREAST_HETERO_HHOST"
}
}
]
},
6.3.4.6. 机密计算
支持用户定义的模型
SELECT TESTA(TEST_B_1.B1,TEST_C_1.C1) FROM TEST_B_1,TEST_C_1
任务结构
"module": {
"moduleName": "TEE",
"params": {
"methodName": "TESTA",
"domainID": "wx-org3.chainmaker.orgId",
"teeHost": "172.16.12.230",
"teePort": "30091"
}
},
"input": {
"data": [
{
"dataName": "TEST_B_1",
"taskSrc": "",
"dataID": "TEST_B_1",
"domainID": "wx-org2.chainmaker.orgId",
"role": "client",
"params": {
"table": "TEST_B_1",
"field": "B1",
"type": "3"
}
},
{
"dataName": "TEST_C_1",
"taskSrc": "",
"dataID": "TEST_C_1",
"domainID": "wx-org3.chainmaker.orgId",
"role": "client",
"params": {
"table": "TEST_C_1",
"field": "C1",
"type": "3"
}
}
]
},
6.3.4.7. 服务类型
支持匿名查询PIR
SELECT * FROM TEST_B_1 WHERE TEST_B_1.ID=?
服务模板
{
"id": "",
"version": "1.0.0",
"orgId": "",
"serviceClass": "PirClient4Query",
"serviceName": "匿名查询接收方",
"nodePort": "",
"manual": "false",
"exposeEndpoints": [{
"name": "PirClient",
"form": [
{
"key": "description",
"values": "匿名查询接收方服务",
"labels": "服务描述",
"types": "INPUT"
},
{
"key": "tlsEnabled",
"values": true,
"labels": "通信加密",
"types": "CHECKBOX",
"desc":"启用TLS"
},
{
"key": "serviceCa",
"values": "",
"labels": "签名证书",
"types": "TEXTAREA"
},
{
"key": "serviceCert",
"values": "",
"labels": "加密证书",
"types": "TEXTAREA"
},
{
"key": "serviceKey",
"values": "",
"labels": "加密私钥",
"types": "TEXTAREA"
},
{
"key": "protocol",
"values": "HTTP",
"labels": "通信协议",
"types": "SELECT",
"options": [
{
"value": "HTTP",
"label": "HTTP"
},
{
"value": "GRPC",
"label": "GRPC"
}
]
}]
}],
"referEndpoints": [
{
"name": "PirServer",
"referServiceID": "",
"referEndpointName": "PirServer",
"protocol": "HTTP",
"serviceCa": "",
"serviceCert": ""
}
],
"values": [
{
"key": "",
"value": ""
}
],
"referValues": [
{
"key": "",
"referServiceID": "",
"referKey": ""
}
]
}
6.3.5. PQL引擎设计和实现
6.3.5.1. 关键模块设计
PQL模块主要分为以下模块:
语法模块
解析模块
优化模块
任务构建模块
6.3.5.2. 语法模块
PQL语法解析使用ANTLR4工具,将用户输入的SQL语句转换为抽象语法树AST,并提供遍历AST的接口。
ANTLR4可以根据语法定义文件生成解析器,解析器可以构建和遍历语法树。这里语法定义文件为后缀是.g4的文件,生成的解析器相关代码在/gen目录下。
编译器IntelliJ安装插件ANTLR4后可以直接查看SQL语句对应的语法树
例如,将SQL语句 SELECT ADATA.A1 FROM ADATA,BDATA WHERE ADATA.ID=BDATA.ID通过语法文件解析成语法树后,如下图所示:
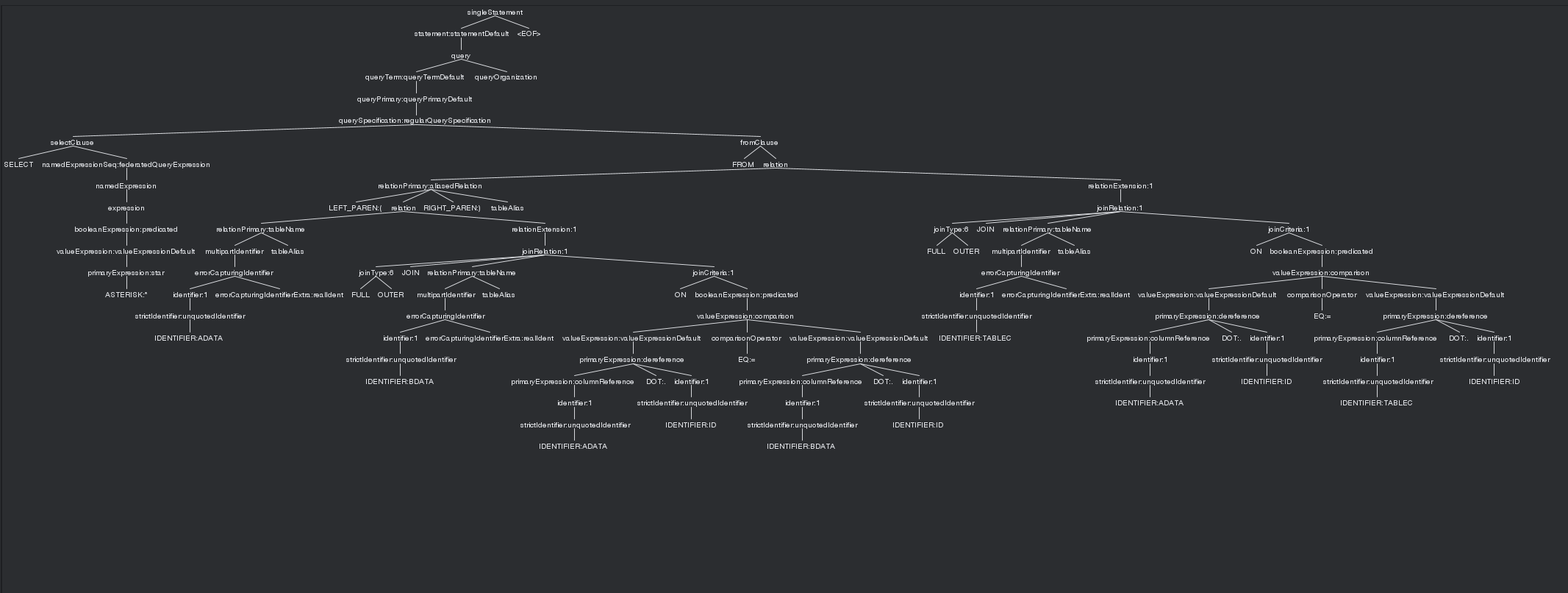
语法定义文件分为词法部分和语法部分,在本项目中对应的是SqlBaseLexer.g4和SqlBaseParser.g4,Lexer定义了查询语言支持的所有单词符号,Parser定义了支持的所有语法逻辑。PQL项目通过修改语法定义文件,在SQL的基础上增加了FL、TEE等特殊语法的支持。并通过ANTLR4工具由g4文件生成SqlBaseParser、SqlBaseParserVistor等代码文件,提供语法树的生成与遍历接口。
6.3.5.3. 解析模块
解析模块是完成语法树到逻辑计划的转换,主要是基于上述语法树和解析器,遍历整棵语法树并将对应语义转换为逻辑计划算子。
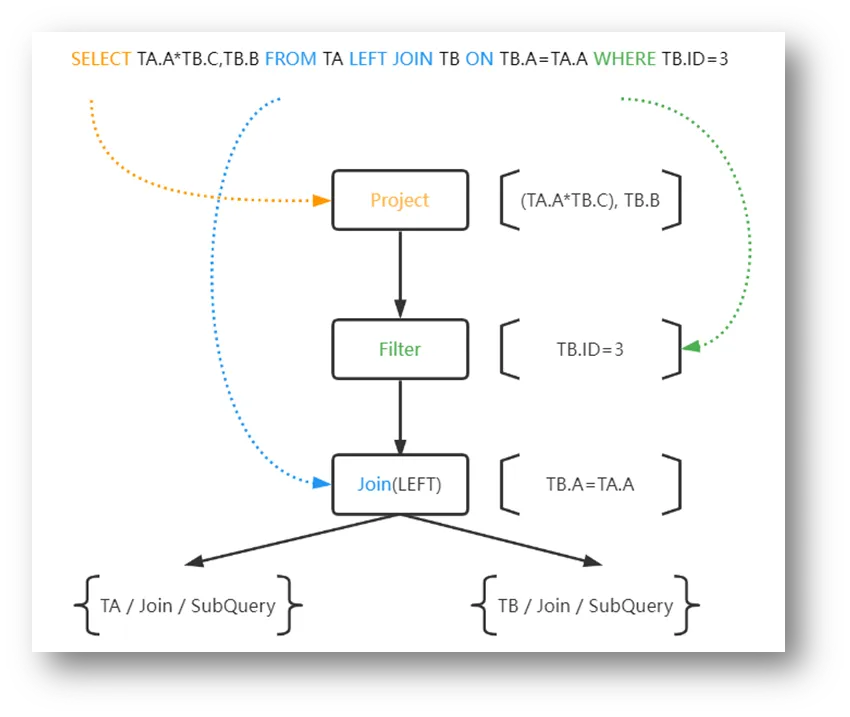
逻辑算子如下所示:
SELECT /*+ TEEJOIN */ SUM(TEST_B_1.B1+TEST_C_1.C1) FROM TEST_B_1 JOIN TEST_C_1 ON TEST_B_1.ID=TEST_C_1.ID WHERE TEST_B_1.B2>5
| 逻辑算子 | 表达 | 说明 |
|---|---|---|
| LogicalTable | FROM ... , ... | 源数据 |
| LogicalFilter | WHERE ...>... | 过滤 |
| LogicalJoin | FROM ... JOIN ... ON ... | |
| WHERE ...=... | 求交 | |
| LogicalProject | SELECT ... | |
| SELECT ...+... | 表达式 | |
| LogicalAggregate | SELECT SUM()... | 聚合 |
| LogicalHint | SELECT /+ ... / ... | 指定特定算子 |
| FederatedLearning | SELECT FL()... | 联邦学习 |
遍历语法树中的表达语句,生成对应的逻辑算子,并按照逻辑执行顺序构成一棵逻辑计划树。
6.3.5.4. 优化模块
优化模块集成了Calcite的优化器,优化器主要输入有三部分:元数据、逻辑计划、规则与代价。 基于上面三个部分可以生成优化后的执行计划。PQL项目的解析器和优化器是两个模块,因此做了逻辑计划的转换,将独立的逻辑计划转换为Calcite结构的逻辑计划,从而实现进一步优化。
转换器:calcite/converter、calcite/adapter
元数据:calcite/optimizer/metadata
逻辑计划:calcite/relnode
规则与代价:calcite/cost
6.3.5.5. 任务构建模块
任务构建类JobBuilderWithOptimizer通过遍历优化器生成的计划树,生成对应的任务结构,同时做了一些特殊场景的逻辑处理,这部分代码需要进一步优化。
6.4. 隐私计算引擎设计
6.4.1. MPC安全多方计算协议
使用方案:SPDZ <br/>
算法论文:SPDZ2k: Efficient MPC mod 2^k for Dishonest Majority <br/>
论文出处:International Cryptology Conference. CRYPTO 2018: Advances in Cryptology – CRYPTO 2018(三大密码顶会之一,CCF.A)
6.4.1.1. 加法计算过程
以两方为例
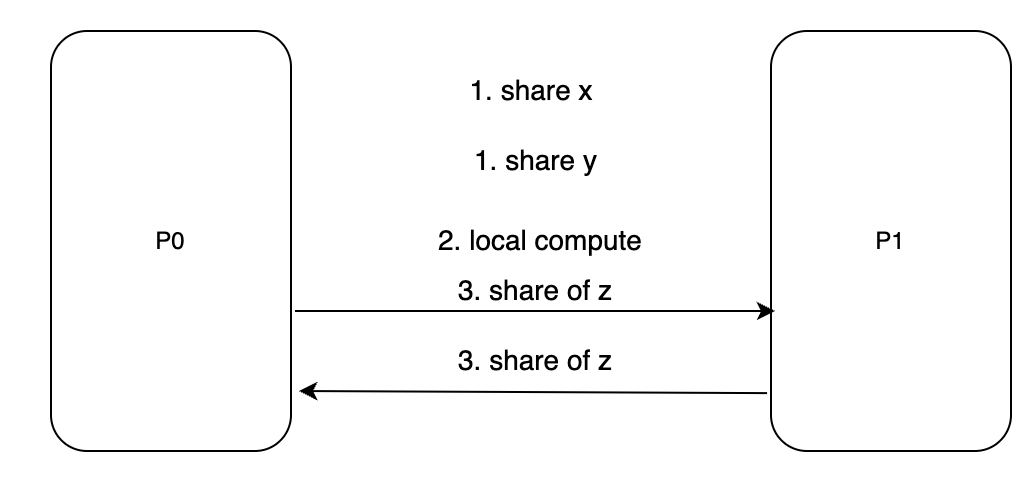
所有参与方本地计算 <br/>1. P0、P1处理各自的数据,变成分片形式 <br/>2. P0、P1本地计算加法 <br/>3. P0、P1互相发送结果的分片,还原成明文
6.4.1.2. 乘法计算过程
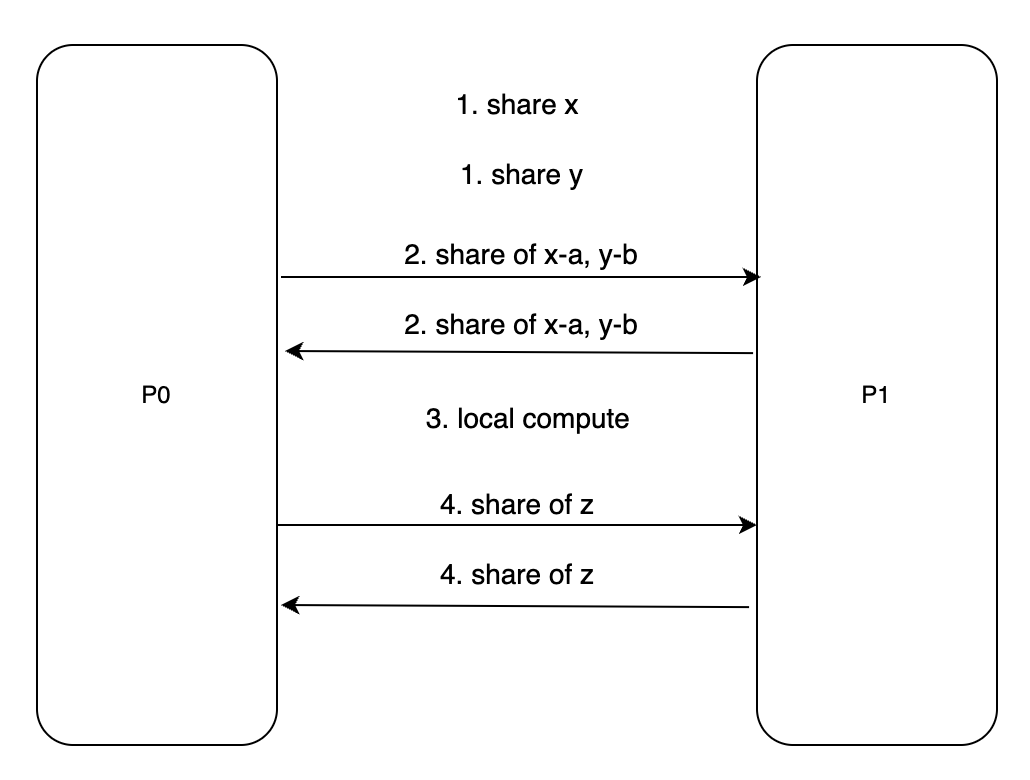
P0、P1处理各自的数据,变成分片形式[x]、[y]
<br/>选择一个三元组([a], [b], [c]),P0与P1互相发送各自拥有的分片[e] = [x] - [a], [f] = [y] - [b]
<br/>分片加和还原出明文,P0、P1本地计算
<br/>P0: [z] = [x * y] = [c] + e * [b] + f * [a] + e * f<br/>P1: [z] = [x * y] = [c] + e * [b] + f * [a]<br/>P0与P1互相发送各自的[z]分片,还原出明文z
6.4.2. 隐私求交协议
使用方案:RR22 <br/>
论文题目:Blazing Fast PSI from Improved OKVS and Subfield VOLE <br/>
论文出处:CCS’22(是国际公认的信息安全领域旗舰会议,信息安全领域出名的四大顶级会议之一,CCF推荐A类会议) <br/>
6.4.2.1. 算法协议

6.4.2.2. 算法流程
协议使用OKVS以及VOLE构建OPRF,再使用OPRF构建两方PSI。
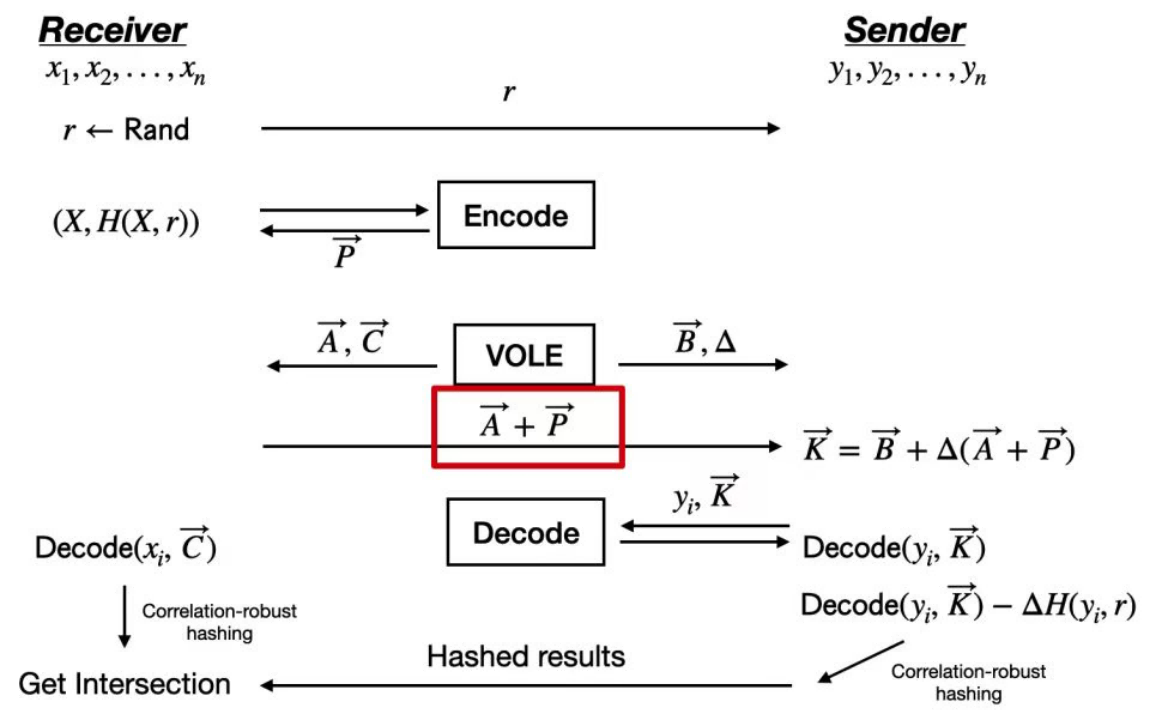
Receiver随机采样r,并发送;
<br/>Receiver使用(X,H(X,r))进行编码,得到向量P;
<br/>Receiver和Sender调用VOLE,Receiver获得向量A和C,Sender获得向量B和Δ;
<br/>Receiver发送A+P,Sender收到后计算K=B+Δ(A+P);
<br/>Sender使用y和K进行解码,得到Decode(y,K);
<br/>Sender发送Decode(y,K)-ΔH(y,r),Receiver接收到后与Decode(x,C)求交集。
6.4.3. 匿名查询协议
使用方案:APSI <br/>
论文题目:Labeled PSI from Homomorphic Encryption with Reduced Computation and Communication <br/>
论文出处:CCS’21(是国际公认的信息安全领域旗舰会议,信息安全领域出名的四大顶级会议之一,CCF推荐A类会议)
6.4.3.1. 算法流程
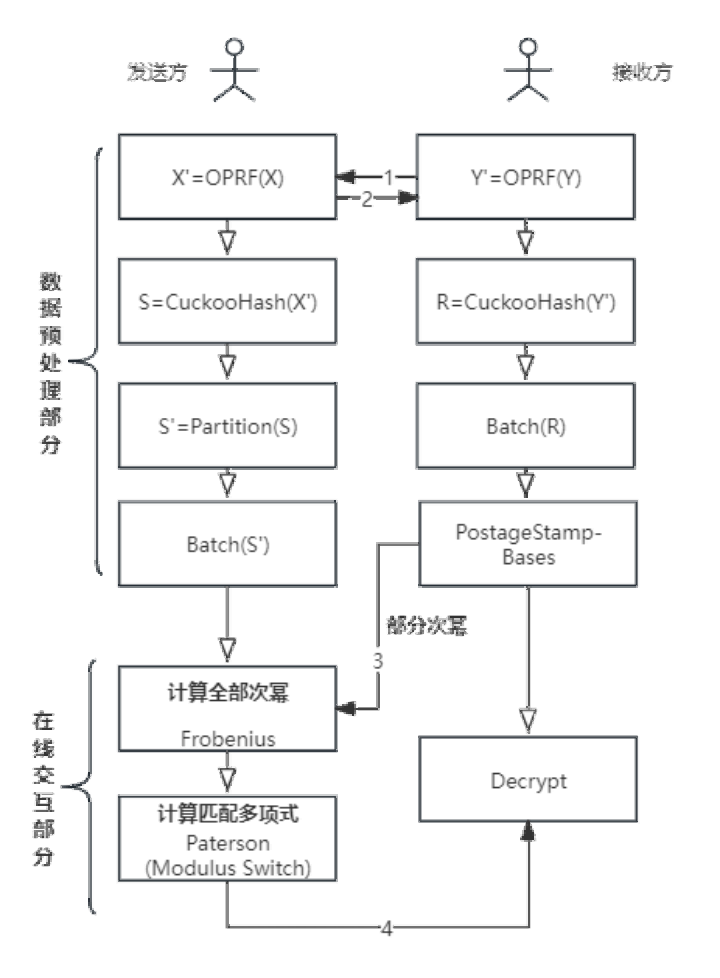
1. 数据预处理部分 <br/>1) 两方先使用OPRF,将数据随机化,保证数据安全,防止恶意的接收者攻击,然后使用布谷鸟哈希,将其插入到哈希表表中,起到压缩数据和混淆功能,降低计算量;具体而言,接收方发送OPRF请求到发送方,发送方返回响应,接收方根据响应提取OPRF输出,并以OPRF的输出插入布谷鸟哈希表。同时发送方计算自己的OPRF,并以OPRF的输出插入布谷鸟哈希表。<br/>2) 发送方(Sender)先对哈希表进行分块,然后对每个子表进行打包,计算每个子表匹配多项式的系数;具体而言,APSI支持对以上分块打包的参数进行配置。table_size表示使用的布谷鸟哈希表的大小,也即子表的行数。max_items_per_bin表示每个子表的列数。hash_func_count为布谷鸟哈希所使用的Hash函数的个数,一般配置为2-4,发送方需要为每个Hash函数生成一个独立的哈希表。Sender在构建布谷鸟哈希表的过程中,不使用踢出操作,而是在同一行的尾部追加;如果子表已满(本行的列数到达max_items_per_bin)则追加在相邻子表的同一行。打包操作则是把每个子表的每一行作为匹配多项式,进行打包计算多项式系数。<br/>3) 接收方(Receiver)利用batch先将哈希表打包为明文多项式,然后使用扩展邮票基技术(extremal postage-stamp bases)选择要预计算的部分次幂。
2. 在线交互部分 <br/>1) 接收方(Receiver)将预计算的部分次幂加密,发送给发送方;<br/>2) 发送方(Sender)先利用弗罗贝纽斯技术(Frobenius operation)同态计算出发送者数据的全部次幂,然后利用佩特森算法(Paterson Stockmeyer algorithm)计算求交多项式,若计算结果较大,则使用模交换(Modulus Switch)降低密文大小,最后返回给接收方;<br/>3) 接收方(Receiver)对收到的信息解密,通过部分解密结果是否为0判断是否是交集元素,如果是则解密另一部分内容得到查询结果。
6.5. 可信计算服务合约设计
可信计算服务智能合约(contract_mira),基于长安链合约go-sdk开发,主要包含以下几个功能模块:
计算资源管理
计算模型管理
计算任务管理
6.5.1. 计算资源管理&计算模型管理
6.5.1.1. 合约接口
| 接口名 | 所属模块 | 功能描述 |
|---|---|---|
| RepublishComputingResource | 计算资源管理 | 重新发布计算资源 |
| DeleteComputingResource | 计算资源管理 | 删除计算资源 |
| GetComputingResourceAll | 计算资源管理 | 获取全部计算资源 |
| GetComputingResourceByPartyId | 计算资源管理 | 根据PartyId获取计算资源 |
| GetComputingResource | 计算资源管理 | 获取计算资源 |
| CreateComputingModel | 机密计算模型管理 | 创建计算模型 |
| GetComputingModelList | 机密计算模型管理 | 获取计算列表 |
| GetComputingModel | 机密计算模型管理 | 获取计算模型详情 |
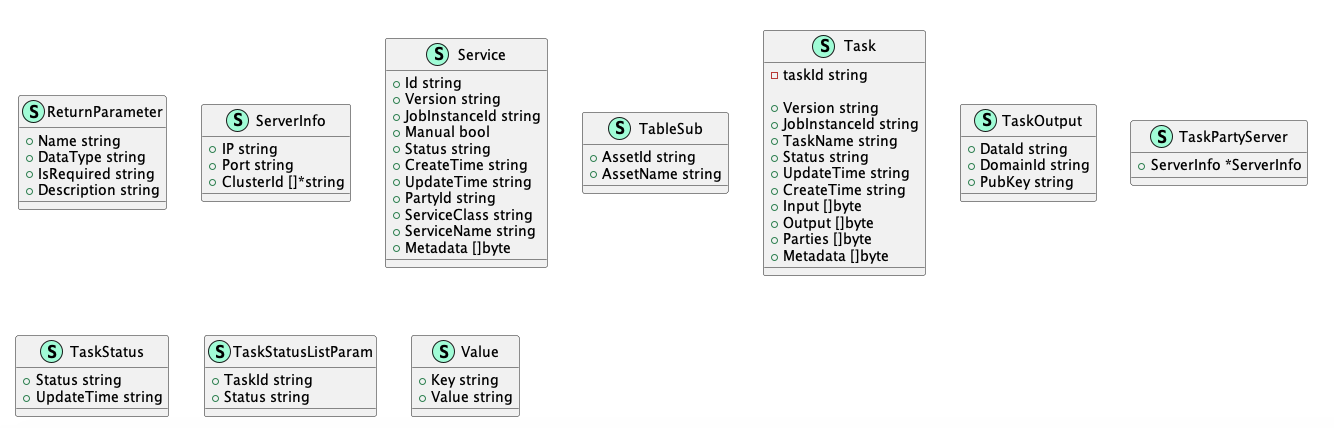
6.5.1.2. 关键数据结构UML
计算资源
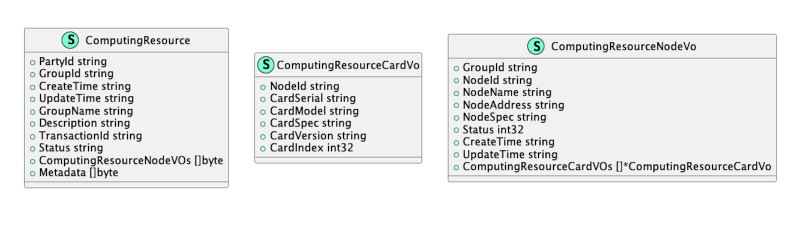
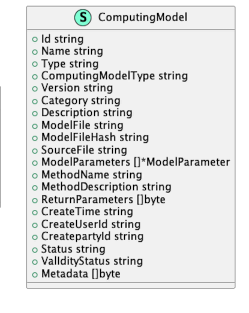
计算模型
6.5.2. 计算任务管理
6.5.2.1. 合约接口
| 接口名 | 所属模块 | 功能描述 |
|---|---|---|
| CreateJob | 计算任务管理 | 创建job |
| CreateJobApprove | 计算任务管理 | 创建任务审批 |
| GetJob | 计算任务管理 | 获取job详情 |
| GetJobApprove | 计算任务管理 | 获取job审批详情 |
| SetJobStatus | 计算任务管理 | 设置job状态 |
| GetDataFromKey | 计算任务管理 | 根据key获取数据 |
| QueryServiceDetails | 计算任务管理 | 查询服务详情 |
| QueryTaskDetails | 计算任务管理 | 查询任务详情 |
| UpdateJobTriggerEnable | 计算任务管理 | 更新job实例触发器状态 |
| UpdateServiceStatus | 计算任务管理 | 更新服务状态 |
| SetTaskOutput | 计算任务管理 | 设置任务结果 |
| SetResultServerAddr | 计算任务管理 | 设置服务结果地址 |
| GetResultServerAddr | 计算任务管理 | 获取服务结果地址 |
| CreateJobInstance | 计算任务管理 | 创建Job实例 |
| SetJobInstanceStatusReady | 计算任务管理 | 设置job实例状态为就绪 |
| UpdateJobInstance | 计算任务管理 | 更新job实例 |
| GetJobInstanceInfo | 计算任务管理 | 获取job实例信息 |
| GetJobInstanceDetail | 计算任务管理 | 获取job实例详情 |
| CancelJobInstance | 计算任务管理 | 取消job 实例 |
| UpdateJobInstanceFailedReason | 计算任务管理 | 更新job实例失败原因 |
| SetTaskPartyInfo | 计算任务管理 | 设置task参与者信息 |
| SetTaskStatus | 计算任务管理 | 设置task状态 |
6.5.2.2. 关键数据结构UML