1. 高性能交易调度技术文档
1.1. 陈旧读检测与容器回退机制完整技术文档
1.1.1. 执行摘要
本文档系统地分析了长安链在高并发交易执行过程中,staleRead 和 staleReadKeys 字段从陈旧读检测、层层传递到最终在容器中参与回退算法的完整流程。
涉及的核心模块:
Snapshot - 陈旧读检测与记录
Scheduler - 交易调度与重执行
VmManager - 虚拟机管理与运行时实例复用
Runtime - 运行时层陈旧读传递
TxHandler/SDK - 容器内部回退逻辑
1.1.2. 架构全景
1.1.2.1. 端到端数据流
┌─────────────────────────────────────────────────────────────────────┐
│ Chainmaker-Go 主链 │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Snapshot │───→│Scheduler │───→│VmManager │───→│ Runtime │ │
│ │ 冲突检测 │ │ 交易调度 │ │ VM管理层 │ │ 运行时 │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
│ │ │ │
│ │ AddStaleReadKey() │ │
│ │ flushLatestStaleReadToTx() │ │
│ │ │ │
│ └─→ TxSimContext.SetStaleRead() │ │
│ ↓ │ │
│ txSimContext.staleRead = "contract#key" │ │
│ ↓ │ │
│ executeTx() │ │
│ ↓ │ │
│ invokeUserContractByRuntime() ←───────────────────┤ │
│ (运行时实例复用 - 关键优化点) │ │
│ ↓ │ │
│ runtimeInstance.Invoke() │ │
│ ↓ │ │
│ txSimContext.GetStaleRead() ────────────────→ staleRead │
│ ↓ │ │
│ dockerVMMsg.Request.StaleRead = staleRead │ │
│ │ │ │
└─────────────────────┼─────────────────────────────────────┼──────────┘
│ │
│ gRPC 通道 │
↓ ↓
┌─────────────────────────────────────────────────────────────────────┐
│ Contract-SDK-Go 容器侧 │
│ │
│ ┌──────────┐ ┌──────────┐ │
│ │TxHandler │────────────────────────────→│ SDK │ │
│ │接收请求 │ SetStaleRead(staleRead) │ 部分回退 │ │
│ └──────────┘ └──────────┘ │
│ │ │ │
│ │ msg.Request.StaleRead │ │
│ ↓ ↓ │
│ staleRead = "contract#key" GetStateByte() │
│ │ │ │
│ │ SetPReadMap(历史读集) │ │
│ ↓ ↓ │
│ s.SetStaleRead(staleRead) if key == staleRead: │
│ s.SetPReadMap(pReadMap) 清空标记,从链上读取 │
│ else: │
│ 从 pReadMap 返回历史值 │
└─────────────────────────────────────────────────────────────────────┘
1.1.3. 完整执行流程
1.1.3.1. 阶段 1:陈旧读检测(Snapshot 模块)
文件:snapshot_impl.go
1.1.3.1.1. 检测逻辑
// 第369-463行:ApplyTxSimContext 方法
func (s *SnapshotImpl) ApplyTxSimContext(
txSimContext protocol.TxSimContext,
specialTxType protocol.ExecOrderTxType,
runVmSuccess bool,
applySpecialTx bool) (bool, int) {
tx := txSimContext.GetTx()
txExecSeq := txSimContext.GetTxExecSeq()
txRWSet := txSimContext.GetTxRWSet(runVmSuccess)
// ============================================================
// 第一次冲突检查(乐观检查)
// ============================================================
for _, txRead := range txRWSet.TxReads {
finalKey := constructKey(txRead.ContractName, txRead.Key)
if sv, ok := s.writeTable.getByLock(finalKey); ok {
// 检查序列号:是否有更新的写入
if sv.seq >= txExecSeq {
// ⚠️ 检测到陈旧读冲突
s.log.Infof("[STALEREAD-DETECT] tx=%s, stale key=%s, sv.seq=%d, txExecSeq=%d",
tx.Payload.TxId, finalKey, sv.seq, txExecSeq)
// ✅ 步骤1:添加陈旧读键到列表
s.AddStaleReadKey(finalKey)
// ✅ 步骤2:回灌最新陈旧读键到 TxSimContext
s.flushLatestStaleReadToTx(txSimContext)
// 返回失败,触发重执行
return false, len(s.txTable) + len(s.specialTxTable)
}
}
}
// 应用写集到写表
s.applyWriteSetToWriteTable(txRWSet, txExecSeq)
// ============================================================
// 第二次冲突检查(Double-Check)
// ============================================================
finalReadKvs := s.buildFinalReadKvs(txRWSet)
for finalKey := range finalReadKvs {
if sv, ok := s.writeTable.getByLock(finalKey); ok {
if sv.seq >= txExecSeq {
// 再次检测到冲突
s.log.Info("[STALEREAD-DOUBLECHECK] tx=%s, key=%s",
tx.Payload.TxId, finalKey)
s.AddStaleReadKey(finalKey)
s.flushLatestStaleReadToTx(txSimContext)
return false, s.GetSnapshotSize() + len(s.specialTxTable)
}
}
}
// 应用成功
return true, s.GetSnapshotSize()
}
1.1.3.1.2. 回灌到 TxSimContext
// 第350-367行:flushLatestStaleReadToTx 方法
func (s *SnapshotImpl) flushLatestStaleReadToTx(txSimContext protocol.TxSimContext) {
if len(s.staleReadKeys) == 0 {
return
}
// 取最后一个作为最新陈旧读
latest := s.staleReadKeys[len(s.staleReadKeys)-1]
// 检查是否实现了 staleSetter 接口
if setter, ok := txSimContext.(staleSetter); ok {
// ✅ 设置陈旧读键到 TxSimContext
setter.SetStaleRead(latest)
s.log.Warnf("[STALEREAD-FLUSH] set stale key to txSimContext: %s", latest)
} else {
s.log.Warnf("[STALEREAD-FLUSH] txSimContext does not implement SetStaleRead")
}
// 清空列表,避免数据串联
s.staleReadKeys = s.staleReadKeys[:0]
}
1.1.3.2. 阶段 2:Scheduler 调度重执行
文件:chainmaker-go/module/core/common/scheduler/scheduler.go
1.1.3.2.1. 交易处理
// 第333-350行:handleTx 方法
func (ts *TxScheduler) handleTx(
tx *commonPb.Transaction,
snapshot protocol.Snapshot,
block *commonPb.Block) (applyResult bool, err error) {
// ✅ 执行交易
txSimContext, specialTxType, runVmSuccess := ts.executeTx(
tx, snapshot, block, senderCollection)
// ✅ 应用到 Snapshot(可能检测到陈旧读)
applyResult, applySize := snapshot.ApplyTxSimContext(
txSimContext,
specialTxType,
runVmSuccess,
false)
if !applyResult {
// 应用失败,说明检测到陈旧读
// txSimContext 中已包含 staleRead 信息
ts.log.Warnf("[RETRY] tx=%s apply failed, will retry", tx.Payload.TxId)
// ✅ 重新执行(此时 txSimContext.staleRead 不为空)
txSimContext, specialTxType, runVmSuccess = ts.executeTx(
tx, snapshot, block, senderCollection)
// 再次应用
applyResult, applySize = snapshot.ApplyTxSimContext(
txSimContext, specialTxType, runVmSuccess, false)
}
return applyResult, nil
}
1.1.3.2.2. 交易执行
// 第681-771行:executeTx 方法
func (ts *TxScheduler) executeTx(
tx *commonPb.Transaction,
snapshot protocol.Snapshot,
block *commonPb.Block,
collection *SenderCollection) (protocol.TxSimContext, protocol.ExecOrderTxType, bool) {
// ✅ 创建 TxSimContext(继承 staleRead)
txSimContext := vm.NewTxSimContext(ts.VmManager, snapshot, tx,
block.Header.BlockVersion, ts.log)
// 设置执行序列号
execSeq := snapshot.GetSnapshotSize()
txSimContext.SetTxExecSeq(execSeq)
txSimContext.SetSnapshot(snapshot)
// ✅ 根据版本调用虚拟机执行
var txResult *commonPb.Result
var specialTxType protocol.ExecOrderTxType
var err error
blockVersion := block.Header.BlockVersion
if blockVersion >= 2300 {
txResult, specialTxType, err = ts.runVM2300(tx, txSimContext, enableOptimizeChargeGas)
} else if blockVersion >= 2220 {
txResult, specialTxType, err = ts.runVM2220(tx, txSimContext, enableOptimizeChargeGas)
} else {
txResult, specialTxType, err = ts.runVM2210(tx, txSimContext)
}
if err != nil {
runVmSuccess = false
}
// 设置结果
txSimContext.SetTxResult(txResult)
return txSimContext, specialTxType, runVmSuccess
}
1.1.3.3. 阶段 3:VmManager 运行时实例管理
文件:vm/vm_factory.go
1.1.3.3.1. invokeUserContractByRuntime 方法详解
// 第287-408行:invokeUserContractByRuntime 方法
func (m *VmManagerImpl) invokeUserContractByRuntime(
contract *commonPb.Contract,
method string,
parameters map[string][]byte,
txContext protocol.TxSimContext,
byteCode []byte,
gasUsed uint64) (*commonPb.ContractResult, protocol.ExecOrderTxType, commonPb.TxStatusCode) {
contractResult := &commonPb.ContractResult{Code: uint32(1)}
txId := txContext.GetTx().Payload.TxId
txType := txContext.GetTx().Payload.TxType
runtimeType := contract.RuntimeType
m.Log.Debugf("invoke user contract[%s], tx id:%s, runtime:%s, method:%s",
contract.Name, txId, contract.RuntimeType.String(), method)
// ============================================================
// ⭐ 关键优化:交易到运行时实例的映射管理
// ============================================================
var runtimeInstance protocol.RuntimeInstance
var err error
// ✅ 步骤1:检查是否已有运行时实例绑定到此交易
m.txInstanceMutex.RLock()
if instance, exists := m.txInstanceMap[txId]; exists {
runtimeInstance = instance
m.Log.Infof("✅ [REUSE-RUNTIME] Reusing existing runtime instance for tx [%s]", txId)
}
m.txInstanceMutex.RUnlock()
// ✅ 步骤2:如果没有绑定实例,创建新的运行时实例
if runtimeInstance == nil {
// 获取对应运行时类型的实例管理器
vmInstancesManager := m.InstanceManagers[runtimeType]
if vmInstancesManager == nil {
// 错误处理:运行时类型不存在
if runtimeType == commonPb.RuntimeType_GO &&
m.InstanceManagers[commonPb.RuntimeType_DOCKER_GO] != nil {
contractResult.Message = "incorrect vm go runtime version, " +
"you only have docker_go part configured in chainmaker.yml's vm module"
} else {
contractResult.Message = fmt.Sprintf("no such vm runtime %q", runtimeType)
}
return contractResult, protocol.ExecOrderTxTypeNormal,
commonPb.TxStatusCode_INVALID_CONTRACT_PARAMETER_RUNTIME_TYPE
}
// 创建新的运行时实例
runtimeInstance, err = vmInstancesManager.NewRuntimeInstance(
txContext, m.ChainId, method, m.WxvmCodePath, contract, byteCode, m.Log)
if err != nil {
contractResult.Message = fmt.Sprintf("failed to create vm runtime, contract: %s, %s",
contract.Name, err.Error())
return contractResult, protocol.ExecOrderTxTypeNormal,
commonPb.TxStatusCode_CREATE_RUNTIME_INSTANCE_FAILED
}
// ✅ 步骤3:保存映射关系
m.txInstanceMutex.Lock()
m.txInstanceMap[txId] = runtimeInstance
m.txInstanceMutex.Unlock()
m.Log.Infof("✅ [NEW-RUNTIME] Created new runtime instance for tx [%s]", txId)
}
// 获取交易成员信息
sender, creator, origin, orderTxType, statusCode, err := m.getMember(
contract, txContext, runtimeType)
if err != nil {
contractResult.Message = err.Error()
return contractResult, orderTxType, statusCode
}
// 设置参数
m.setParams(parameters, txContext, sender, creator, origin, txId)
// SQL 事务保存点
var dbTransaction protocol.SqlDBTransaction
if m.ChainConf.ChainConfig().Contract.EnableSqlSupport &&
txType != commonPb.TxType_QUERY_CONTRACT {
txKey := commonPb.GetTxKeyWith(txContext.GetBlockProposer().MemberInfo,
txContext.GetBlockHeight())
dbTransaction, err = txContext.GetBlockchainStore().GetDbTransaction(txKey)
if err != nil {
contractResult.Message = fmt.Sprintf("get db transaction from [%s] error %+v",
txKey, err)
return contractResult, protocol.ExecOrderTxTypeNormal,
commonPb.TxStatusCode_INTERNAL_ERROR
}
err := dbTransaction.BeginDbSavePoint(txId)
if err != nil {
m.Log.Warn("[%s] begin db save point error, %s", txId, err.Error())
}
}
// ✅ 步骤4:调用 Invoke 方法(传递 txContext,其中包含 staleRead)
runtimeContractResult, specialTxType := runtimeInstance.Invoke(
contract, method, byteCode, parameters, txContext, gasUsed)
// ============================================================
// ⭐ 步骤5:交易完成后清理映射
// ============================================================
defer func() {
// 成功提交或不需要重试的失败交易,立即清理映射
if runtimeContractResult.Code == 0 ||
specialTxType != protocol.ExecOrderTxTypeIterator {
m.txInstanceMutex.Lock()
delete(m.txInstanceMap, txId)
m.txInstanceMutex.Unlock()
m.Log.Infof("✅ [CLEANUP] Cleaned up runtime instance mapping for tx [%s]", txId)
} else {
m.Log.Infof("⚠️ [KEEP] Keeping runtime instance for retry, tx [%s]", txId)
}
}()
// 返回处理结果
if runtimeContractResult.Code == 0 {
return runtimeContractResult, specialTxType, commonPb.TxStatusCode_SUCCESS
}
// SQL 事务回滚
if m.ChainConf.ChainConfig().Contract.EnableSqlSupport &&
txType != commonPb.TxType_QUERY_CONTRACT {
if err := dbTransaction.RollbackDbSavePoint(txId); err != nil {
m.Log.Warn("[%s] rollback db save point error, %s", txId, err.Error())
}
}
return runtimeContractResult, specialTxType, commonPb.TxStatusCode_CONTRACT_FAIL
}
设计亮点:
运行时实例复用:
第一次执行:创建新实例并缓存到
txInstanceMap陈旧读重试:直接复用缓存的实例
避免重复创建容器连接,显著提升性能
线程安全:
使用
txInstanceMutex保护txInstanceMap读操作用 RLock,写操作用 Lock
清理策略:
交易成功:立即清理映射
交易失败但需要重试:保留映射
通过
specialTxType判断是否需要保留
1.1.3.4. 阶段 4:Runtime 层传递 staleRead
文件:vm-engine/runtime.go
1.1.3.4.1. Invoke 方法核心逻辑
// 第86-95行:Invoke 方法签名
func (r *RuntimeInstance) Invoke(
contract *commonPb.Contract,
method string,
byteCode []byte,
parameters map[string][]byte,
txSimContext protocol.TxSimContext, // ✅ 包含 staleRead
gasUsed uint64,
) (contractResult *commonPb.ContractResult, execOrderTxType protocol.ExecOrderTxType) {
// 获取原始 TxId
originalTxId := txSimContext.GetTx().Payload.TxId
uniqueTxKey := r.clientMgr.GetUniqueTxKey(originalTxId)
r.logger.DebugDynamic(func() string {
return fmt.Sprintf("start handling tx [%s]", originalTxId)
})
// 初始化 contractResult
contractResult = &commonPb.ContractResult{
Code: uint32(1),
Result: nil,
Message: "",
}
// 检查连接状态
if !r.clientMgr.HasActiveConnections() {
r.logger.Errorf("contract engine client stream not ready, tx id: %s", originalTxId)
err := errors.New("contract engine client not connected")
return r.errorResult(contractResult, err, err.Error())
}
specialTxType := protocol.ExecOrderTxTypeNormal
// Gas 计算
// ... (省略 gas 相关代码)
// 删除 CONTRACT 相关参数
for key := range parameters {
if strings.Contains(key, "CONTRACT") {
delete(parameters, key)
}
}
// ============================================================
// ⭐ 构造 Docker VM 消息
// ============================================================
dockerVMMsg, ok := dockerVMMsgPool.Get().(*protogo.DockerVMMessage)
if !ok && txSimContext.GetBlockVersion() >= version235 {
contractResult.Message = "convert docker vm msg failed."
return contractResult, specialTxType
}
// 设置基本字段
dockerVMMsg.ChainId = r.chainId
dockerVMMsg.TxId = uniqueTxKey
dockerVMMsg.Type = protogo.DockerVMType_TX_REQUEST
dockerVMMsg.Request.ChainId = r.chainId
dockerVMMsg.Request.ContractName = contract.Name
dockerVMMsg.Request.ContractVersion = contract.Version
dockerVMMsg.Request.ContractIndex = contract.Index
dockerVMMsg.Request.Method = method
dockerVMMsg.Request.Parameters = parameters
// 设置合约地址
if txSimContext.GetBlockVersion() >= version233 &&
txSimContext.GetBlockVersion() < version300 {
address := contract.Address
chainConfig := txSimContext.GetLastChainConfig()
if chainConfig.Vm.AddrType == configPb.AddrType_ZXL {
address = "ZX" + address
}
dockerVMMsg.Request.ContractAddr = address
}
// 设置跨合约调用信息
dockerVMMsg.CrossContext.CrossInfo = txSimContext.GetCrossInfo()
dockerVMMsg.CrossContext.CurrentDepth = uint32(txSimContext.GetDepth())
// ============================================================
// ⭐ 关键:从 TxSimContext 获取 staleRead 并设置到消息中
// ============================================================
staleRead := txSimContext.GetStaleRead() // ✅ 第176行
if len(staleRead) > 0 {
dockerVMMsg.Request.StaleRead = staleRead // ✅ 第178行
r.logger.Infof("✅ [STALEREAD-PASS] Passing staleRead=%s to container (txId=%s)",
staleRead, originalTxId)
}
dockerVMMsg.StepDurations = make([]*protogo.StepDuration, 0, 4)
defer func() {
dockerVMMsgPool.Put(dockerVMMsg)
}()
// 时间统计
utils.EnterNextStep(dockerVMMsg, protogo.StepType_RUNTIME_PREPARE_TX_REQUEST, func() string {
return strings.Join([]string{"pos", strconv.Itoa(r.clientMgr.GetTxSendChLen())}, ":")
})
startTime := time.Now()
txDuration := utils.NewTxDuration(originalTxId, uniqueTxKey, startTime.UnixNano())
fingerprint := txSimContext.GetBlockFingerprint()
r.addTxDuration(txSimContext, fingerprint, txDuration)
// ✅ 发送消息到容器(通过 gRPC)
// ... (后续发送逻辑)
return contractResult, specialTxType
}
1.1.3.5. 阶段 5:容器接收与处理
文件:contract-sdk-go/sandbox/tx_handler.go
1.1.3.5.1. TxHandler 处理 staleRead
// 第138-194行:handleTxRequest 方法
func (h *TxHandler) handleTxRequest(msg *protogo.DockerVMMessage) error {
h.chainId = msg.ChainId
h.txId = msg.TxId
h.originalTxId = getOriginalTxId(h.txId)
h.crossCtx = msg.CrossContext
// ✅ 从 Request 中获取 staleRead(第145行)
staleRead := msg.Request.StaleRead
// 时间统计
startTime := time.Now()
currentTxDuration.Reset(msg, startTime.UnixNano())
currentStatus = BeforeExecute
defer func() {
currentTxDuration.TotalDuration = time.Since(startTime).Nanoseconds()
h.sandboxLogger.Debugf(currentTxDuration.ToString())
}()
args := msg.GetRequest().GetParameters()
// ✅ 创建 SDK 实例
s := sdk.NewSDK(
h.crossCtx,
h.sendSyscallMsg,
h.txId,
h.originalTxId,
h.chainId,
h.contractName,
h.contractAddr,
h.contractLogger,
h.sandboxLogger,
args,
)
sdk.Instance = s
// ============================================================
// ⭐ 处理陈旧读(部分回退)
// ============================================================
if !h.disablePartialRollback && len(staleRead) != 0 {
// ✅ 设置陈旧读键到 SDK(第173-174行)
s.SetStaleRead(staleRead)
// ✅ 从持久化读写集中恢复历史读集
if rw, ok := h.persistentRWSet[h.txId]; ok {
pReadSet := rw.GetReadMap()
s.SetPReadMap(pReadSet)
h.sandboxLogger.Debugf("✅ [PARTIAL-ROLLBACK] Recovered %d read keys from persistentRWSet for tx=%s",
len(pReadSet), h.txId)
} else {
h.sandboxLogger.Warnf("⚠️ [PARTIAL-ROLLBACK] No persistentRWSet found for tx=%s", h.txId)
}
}
// ✅ 执行合约
method := msg.Request.Method
var response protogo.Response
switch method {
case _initContract:
response = h.contract.InitContract()
case _upgradeContract:
response = h.contract.UpgradeContract()
default:
response = h.contract.InvokeContract(method)
}
// 获取读写集和事件
writeMap := s.GetWriteMap()
readMap := s.GetReadMap()
events := s.GetEvents()
// ✅ 缓存读写集供下次可能的重执行使用(第223-228行)
if !h.disablePartialRollback {
h.persistentRWSet[h.txId] = rwset{
readMap: readMap,
writeMap: writeMap,
}
h.sandboxLogger.Debugf("✅ [CACHE-RWSET] Cached %d reads, %d writes for tx=%s",
len(readMap), len(writeMap), h.txId)
}
// 构造响应消息
txResponse := &protogo.TxResponse{
TxId: h.txId,
ChainId: h.chainId,
Code: protogo.DockerVMCode_OK,
Result: response.Payload,
Message: "Success",
WriteMap: writeMap,
ReadMap: readMap,
Events: responseEvents,
}
respMsg := &protogo.DockerVMMessage{
ChainId: h.chainId,
TxId: h.txId,
Type: protogo.DockerVMType_TX_RESPONSE,
Response: txResponse,
}
h.sendResponse(respMsg)
return nil
}
1.1.3.5.2. SDK 读操作拦截
文件:contract-sdk-go/sdk/sdk.go
// 第198-256行:GetStateByte 方法
func (s *SDK) GetStateByte(key, field string) ([]byte, error) {
s.sandboxLogger.Debugf("get state for [%s#%s]", key, field)
// 检查参数合法性
if err := protocol.CheckKeyFieldStr(key, field); err != nil {
return nil, err
}
// ============================================================
// ⭐ 部分回退核心逻辑
// ============================================================
if len(s.staleRead) > 0 {
contractKey := s.constructKey(key, field)
if s.staleRead == contractKey {
// ✅ 到达陈旧读位置,清空标记,开始重新执行
s.sandboxLogger.Infof("✅ [PARTIAL-ROLLBACK] Reached stale read key: %s, " +
"clearing marker and re-executing from here", contractKey)
s.SetStaleRead("")
s.SetPReadMap(nil)
// 后续将正常从链上读取
} else {
// ✅ 未到达陈旧读位置,从历史读集返回缓存值
s.sandboxLogger.Infof("✅ [PARTIAL-ROLLBACK] Before stale read key (%s), " +
"reading cached value for key: %s", s.staleRead, contractKey)
if value, ok := s.pReadMap[contractKey]; ok {
// 直接返回历史值,跳过链上读取
s.sandboxLogger.Debugf("✅ [CACHE-HIT] Returning cached value (len=%d) for key: %s",
len(value), contractKey)
return value, nil
}
// 理论上不应该到这里
s.sandboxLogger.Warnf("⚠️ [CACHE-MISS] Key %s not found in pReadMap, " +
"fallback to normal read", contractKey)
}
}
// ============================================================
// 正常执行路径
// ============================================================
// 1. 尝试从写集读取
if value, done := s.getFromWriteSet(key, field); done {
s.sandboxLogger.Debugf("Read from write set: key=%s#%s", key, field)
return value, nil
}
// 2. 尝试从读集读取
if value, done := s.getFromReadSet(key, field); done {
s.sandboxLogger.Debugf("Read from read set: key=%s#%s", key, field)
return value, nil
}
// 3. 从链上读取
s.sandboxLogger.Debugf("Reading from chain: key=%s#%s", key, field)
return s.getState(key, field)
}
// 第537-545行:Set/Get 方法
func (s *SDK) SetStaleRead(staleRead string) {
s.staleRead = staleRead
}
func (s *SDK) GetStaleRead() string {
return s.staleRead
}
func (s *SDK) SetPReadMap(pReadMap map[string][]byte) {
s.pReadMap = pReadMap
}
算法要点:
位置判断:
key == staleRead→ 到达冲突位置,清空标记key != staleRead→ 未到达,从pReadMap返回
历史数据复用:
缓存上次执行的所有读操作
陈旧读之前的读操作直接返回缓存值
清理机制:
到达陈旧读位置后清空标记
后续操作按正常流程执行
1.1.4. 性能优化点
1.1.4.1. 1. 运行时实例复用(VmManager 层)
优化前:
每次重执行都创建新的 RuntimeInstance
↓
重复建立 gRPC 连接
↓
容器初始化开销
优化后:
第一次执行:创建并缓存 RuntimeInstance
↓
陈旧读重试:复用缓存的 RuntimeInstance
↓
避免重复初始化,显著提升性能
代码位置:vm_factory.go:305-348
1.1.4.2. 2. 历史读集缓存(TxHandler 层)
优化前:
陈旧读重执行:从头开始读取所有键
↓
重复链上读取
↓
网络和存储开销
优化后:
第一次执行:缓存所有读操作到 persistentRWSet
↓
陈旧读重试:从 pReadMap 返回历史值
↓
避免重复读取,仅读取陈旧读位置及之后的键
代码位置:tx_handler.go:223-228 和 sdk.go:217-242
1.2. 链上交易调度策略自适应热切换机制技术文档
本文档描述了一种面向两阶段并发区块链系统的链上交易调度策略自适应热切换机制。该机制在不改变既有交易执行语义和共识流程的前提下,引入基于区块内冲突结构的轻量级策略判别逻辑,实现区块粒度、确定性、可验证的调度策略在线切换,以提升系统在不同负载模式下的执行效率与资源利用率。
本机制已在长安链并行执行框架中完成原型实现,设计目标是作为一项可工程落地、可演进、低侵入的调度增强能力,而非替代现有执行或共识模块。
1.2.1. 目录
1.2.2. 1. 背景与设计动机
在支持并行执行的区块链系统中,交易调度策略直接决定了块内交易的并发度、冲突处理方式以及整体执行效率。现有系统通常在部署阶段选择一种固定的调度策略(例如默认并行调度或特定的冲突回退机制),并在整个运行周期内保持不变。
然而,在实际运行环境中,链上负载具有显著的动态性:
不同区块的交易数量和读写冲突密度存在较大差异;
热点合约或账户的出现会改变冲突结构;
同一调度策略在低冲突与高冲突场景下的性能表现差异明显。
传统数据库与事务处理系统中已有大量关于**调度策略热切换(hot switching)**的研究工作,其核心思想是根据运行时负载特征动态选择更合适的执行或并发控制策略。但这些机制通常假设单节点或弱一致性环境,无法直接应用于区块链系统。
在拜占庭容错区块链中,引入热切换机制需要额外满足以下约束:
确定性约束:所有节点在相同区块输入下必须做出完全一致的调度决策;
可验证性约束:调度决策本身需要能够被验证节点独立复算和校验;
共识安全约束:策略切换不得引入新的分叉风险或非确定性行为;
工程约束:机制应尽量复用既有执行框架,避免大规模重构。
本项目提出的链上交易调度策略自适应热切换机制,正是在上述约束下,对传统热切换思想进行的系统化工程实现。
1.2.3. 2. 系统模型与设计约束
1.2.3.1. 2.1 区块链执行模型
系统假设区块链采用两阶段并发执行模型:
在出块节点,交易在区块内被并行调度执行,并构建读写集合;
在验证节点,交易按照确定性的调度路径进行重放与验证;
执行过程中可显式构建交易之间的读写依赖关系,形成冲突图。
调度策略的选择仅影响块内交易的调度与冲突处理方式,不改变交易本身的业务语义和最终状态转移结果。
1.2.3.2. 2.2 设计目标与约束
本机制的设计目标包括:
区块粒度切换:以区块为最小切换单位,避免跨区块状态迁移;
确定性执行:调度决策完全由区块内容与固定参数决定;
低运行开销:在线决策过程仅包含少量数值计算;
无侵入集成:不修改原有交易执行和共识主流程。
所有参与节点在相同区块输入下,必须能够独立、确定地推导出相同的调度策略编号,否则该区块在策略层面被视为无效。
1.2.4. 3. 基于冲突图的调度策略建模
1.2.4.1. 3.1 冲突图抽象
在并行执行阶段,系统基于交易的读写集合构建一张交易冲突图:
图的顶点表示区块内的具体交易;
图的有向边表示交易之间存在读写或写写依赖关系。
传统调度逻辑主要利用该图确定交易的执行顺序。本机制进一步将冲突图视为区块负载与并发特征的结构化描述,作为调度策略选择的输入。
1.2.4.2. 3.2 特征提取
系统在冲突图构建完成后,同步提取一组轻量级统计特征,包括但不限于:
规模特征:顶点数量与边数量,用于反映区块总体负载;
密度特征:冲突图密度,用于刻画依赖关系紧密程度;
度分布特征:平均入度、平均出度及最大度,用于识别热点交易;
扩展特征:在需要时可加入图层数或局部聚集度等指标。
所有特征按照固定顺序排列,形成定长特征向量,保证不同节点在相同区块下得到一致的输入。
1.2.4.3. 3.3 策略判别模型
调度策略选择采用多分类线性判别模型:
每一种候选调度策略对应一个类别;
模型参数在线下基于历史或模拟区块数据训练;
训练完成后,权重和归一化参数被固化到节点软件中。
在线阶段,节点仅需对特征向量进行标准化处理,并计算各策略的线性得分,选择得分最高的策略作为当前区块的推荐调度方案。该过程计算复杂度低、实现简单,适合嵌入高频出块路径。
1.2.5. 4. 区块粒度自适应热切换协议
1.2.5.1. 4.1 协议总体流程
针对每一个新区块,调度策略自适应热切换协议分为四个阶段:
决策生成(出块侧)
出块节点在构建冲突图后,提取特征并运行策略判别模型,生成策略编号,并将其写入区块元数据。决策传播(共识侧)
策略编号随提议区块进入既有共识流程,并被所有共识节点接收。决策验证(验块侧)
验证节点基于区块交易数据独立复算策略编号,并与区块中携带的编号进行比对。策略执行(执行侧)
在区块通过验证后,节点根据最终确认的策略编号加载对应的调度路径,完成交易重放与提交。
1.2.5.2. 4.2 策略一致性验证
调度策略选择被纳入区块有效性验证流程:
若验证节点复算得到的策略编号与区块中携带的编号不一致,则认为区块在策略层面无效;
该机制可有效防止恶意节点篡改调度决策或因配置不一致导致的执行分歧。
通过这种方式,“如何调度执行”被转化为一个可计算、可验证的确定性结果,并纳入共识安全边界。
1.2.6. 5. 工程实现与一致性保障
1.2.6.1. 5.1 参数与模型固化
为避免运行时配置差异引入不确定性:
模型权重、特征均值与标准差以编译期常量形式固化;
节点启动后直接加载至内存,全程不依赖外部配置文件。
1.2.6.2. 5.2 降级与容错机制
在模型参数缺失或特征计算异常等极端情况下,系统可确定性地回退至预设的默认调度策略。该降级路径在所有节点上行为一致,不破坏共识与执行确定性。
1.2.6.3. 5.3 与现有执行框架的关系
本机制仅在冲突图构建完成后追加特征抽取与策略判别逻辑,不修改原有交易执行、DAG 构建和冲突处理流程,可作为独立模块集成到现有并行调度引擎中。
1.2.7. 6. 参考文献
Guo J, Cai P, Wang J, et al. Adaptive optimistic concurrency control for heterogeneous workloads. PVLDB, 2019.
Tang D, Jiang H, Elmore A J. Adaptive Concurrency Control: One Concurrency Control Does Not Fit All. CIDR, 2017.
1.3. 基于冲突图切分的非确定性交易并发调度算法
算法目的:
1.3.1. 在需要携带的读写集尽可能小的前提下将dag进行分割为足够多个子图,保证并发验证时并发度
1.3.2. 算法准备工作:
1(暂时)通过config参数控制是否开启dag分割(后续配合算法切换会选择别的方式控制)
2 通过带缓冲的channel记录交易执行时间,在算法中使用
1.3.3. 算法流程:
1根据交易执行时间得到dag图中节点(交易)的权重
2根据有依赖关系的交易之间读写集重合部分的大小得到边的权重
3对dag中所有的边从大到小进行排序
4根据边与节点权重构建子图,记录图中的割边
5合并割边的读写集,将一切打包至block发送
1.3.3.1. 验证部分算法:
整体流程与长安链无读写集类似,在模拟dag执行部分有所改动。原始的方法对整个dag进行模拟执行,无法保证cpu利用率,本算法对分割后的dag进行模拟执行,割边部分的读写集由propose block提供,类似于拓扑排序过程将交易加入线程池进行并发,最终得到所有交易的完整读写集。后续对完整读写集与交易执行结果验证方式与长安链相同。
例子:假设tx1,tx2,…tx6依次存在读写依赖,txi+1的读依赖于txi的写,在传统的依据dag执行时只能按照tx1到tx6的顺序串行执行。在本算法中propose阶段将tx4读集中依赖于tx3的写集的部分附在propose的块中,在验证执行时能够(tx1 tx2 tx3) (tx4 tx5 tx6)并发执行。 但是在applytxsimcontext(后称为apply)阶段会产生新的问题。
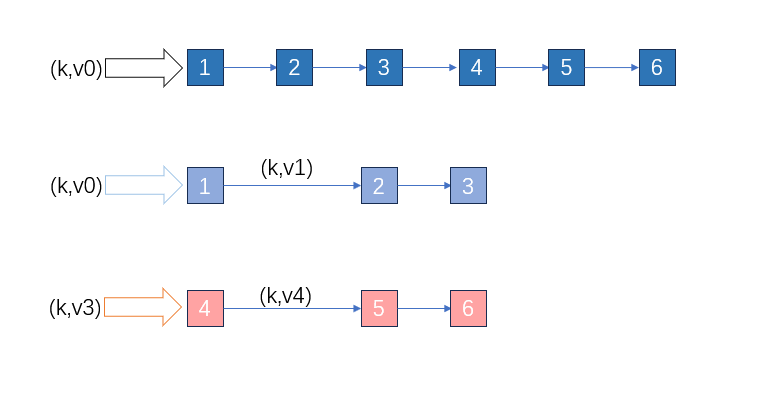 如果tx1与tx4同时apply至一个snapshot,后续的交易很可能读到错误的状态,a方案不同的子图apply到不同的snapshot最终合并;b方案交易根据依赖图从依赖的交易的读写集中读取。本质上来说虽然key相同,但是是不同版本的key同时出现在程序中,最终解决的方法就是同时保存这些kv并使得不同交易能够找到自己应该读取的版本的key。
问题2 如果tx3晚于tx6执行完毕则有可能最终数据版本出现问题,这一点通过txindex即在调度阶段生成的提交顺序索引控制最终状态的更新,当且仅当索引更大时更新table。
如果tx1与tx4同时apply至一个snapshot,后续的交易很可能读到错误的状态,a方案不同的子图apply到不同的snapshot最终合并;b方案交易根据依赖图从依赖的交易的读写集中读取。本质上来说虽然key相同,但是是不同版本的key同时出现在程序中,最终解决的方法就是同时保存这些kv并使得不同交易能够找到自己应该读取的版本的key。
问题2 如果tx3晚于tx6执行完毕则有可能最终数据版本出现问题,这一点通过txindex即在调度阶段生成的提交顺序索引控制最终状态的更新,当且仅当索引更大时更新table。1.3.3.2. 构建子图的流程
输入:原始dag图,节点权重,按照权重从大到小排序后的边集合,子图权重上限
输出:分割后的dag图以及割边集合
流程:遍历边集合,将边的未访问节点尝试加入当前子图,当子图权重(图内节点权重之和)超过阈值时保存当前子图并将节点加入创建的新的子图。最终遍历交易集合将未加入子图的交易加入子图

子图权重上限本质上是为了保证子图的数量足够,如果子图的数量小于 CPU 的核,也就是 k < m,那么会有 CPU 核处于空闲状态,CPU 的利用率不高。实际应用中,k 会被设置为一个远大于核心 数 m 的值(k ≫ m),如此一来,所有的子任务都会被均匀地分配到各个 CPU 核 心,从而减少计算开销。
1.4. 批处理算法
算法流程:
1.4.1. 执行:
每个交易读取当前数据库快照。
• 执行交易逻辑,生成交易的读取集合和写入集合。
• 将写操作保存在局部写集合中。
• 为写入操作创建“写保留”(write reservations),用于冲突检测,发生写冲突时,只保留交易ID最小的写记录,若执行阶段产生冲突,直接回滚,放入下一轮执行。
1.4.2. 提交:
• 并行地对每个交易检查冲突。
• 如果存在写后写(WAW)冲突或读后写(RAW)冲突,则交易回滚。
• 如果没有冲突,应用写操作将更改写入snapshot生效。
1.4.3. 重排序流程
在提交的基础上进行修改,目前主要的冲突依赖为WAW/RAW和WAR三种依赖,由于WAW依赖不可避免,因此我们希望并行执行之后,在提交阶段
能够将RAW和WAR两种依赖都进行提交,这也是目前代码修改中所做的,检测存在两种冲突,有一者存在即可提交。
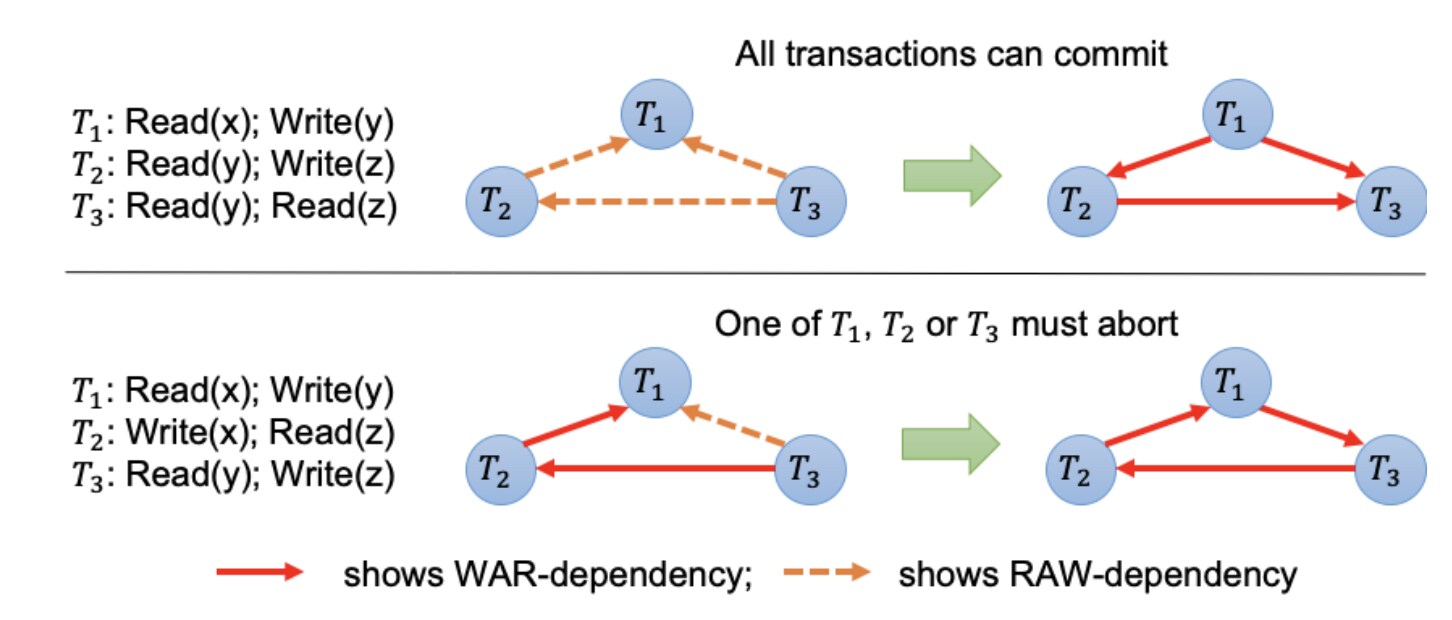 如上图左上角,只有T1可以提交,如果我们修改提交顺序,变成T3->T2->T1那么3个交易都可以提交,因此重排序在提交阶段,首先对WAW进行回滚,而对WAR或者RAW检测的时候,我们规定:不能同时存在WAR和RAW依赖,并且这两种依赖是针对TID比当前交易ID小的Tx而言,还是如上图所示,虽然T2T3对T1有RAW依赖,但是不存在WAR依赖,所以即使当这三个交易都提交之后,结果还是跟T3->T2->T1这个串行化提交的结果保持一致,是可串行化的,符合数据库的规定,因此重排序算法在于减少提交时的回滚数量,提高提交数量。
伪代码:
如上图左上角,只有T1可以提交,如果我们修改提交顺序,变成T3->T2->T1那么3个交易都可以提交,因此重排序在提交阶段,首先对WAW进行回滚,而对WAR或者RAW检测的时候,我们规定:不能同时存在WAR和RAW依赖,并且这两种依赖是针对TID比当前交易ID小的Tx而言,还是如上图所示,虽然T2T3对T1有RAW依赖,但是不存在WAR依赖,所以即使当这三个交易都提交之后,结果还是跟T3->T2->T1这个串行化提交的结果保持一致,是可串行化的,符合数据库的规定,因此重排序算法在于减少提交时的回滚数量,提高提交数量。
伪代码:
执行阶段:对应handleTx中的executeTx
Function: Execute(T, db)
Read from the latest snapshot of db(snapshot已在长安链已涉及)
Execute to compute T’s read/write set (RS & WS)
Function: ReserveWrite(T, writes)
for each key in T.WS:
writes[key] = min(writes[key], T.TID) (wirtes表即长安链中的writeTable)
提交:在长安链中为applyTxSimContext也就是将执行结果写入snapshot的阶段
Function: Commit(T, db, writes)(在applyTxSimContexjt检查3种依赖【包括重排序WAR和RAW的两种依赖】,不符合的返回false)
if HasConflicts(T.TID, T.RS ⋃ T.WS, writes) == false:
Install(T, db)(继续走原始的context生效到snapshot的逻辑)
Function: HasConflicts(TID, keys, reservations)
for each key in keys:
if key in reservations and reservations[key] < TID:
return true
return false
Function: Install(T, db)
for each key in T.WS:
write(key, db)
重排序算法:
Function: ReserveRead(T, reads)(写表WriteTable已在长安链中有涉及,可直接使用)
for each key in T.RS:
reads[key] = min(reads[key], T.TID)
Function: Commit(T, db, reads, writes)
if WAW(T, writes):
return
if WAR(T, reads) == false or RAW(T, writes) == false:
Install(T, db)
Function: WAW(T, writes) = HasConflicts(T.TID, T.WS, writes)
Function: WAR(T, reads) = HasConflicts(T.TID, T.WS, reads)
Function: RAW(T, writes) = HasConflicts(T.TID, T.RS, writes)
流程图:
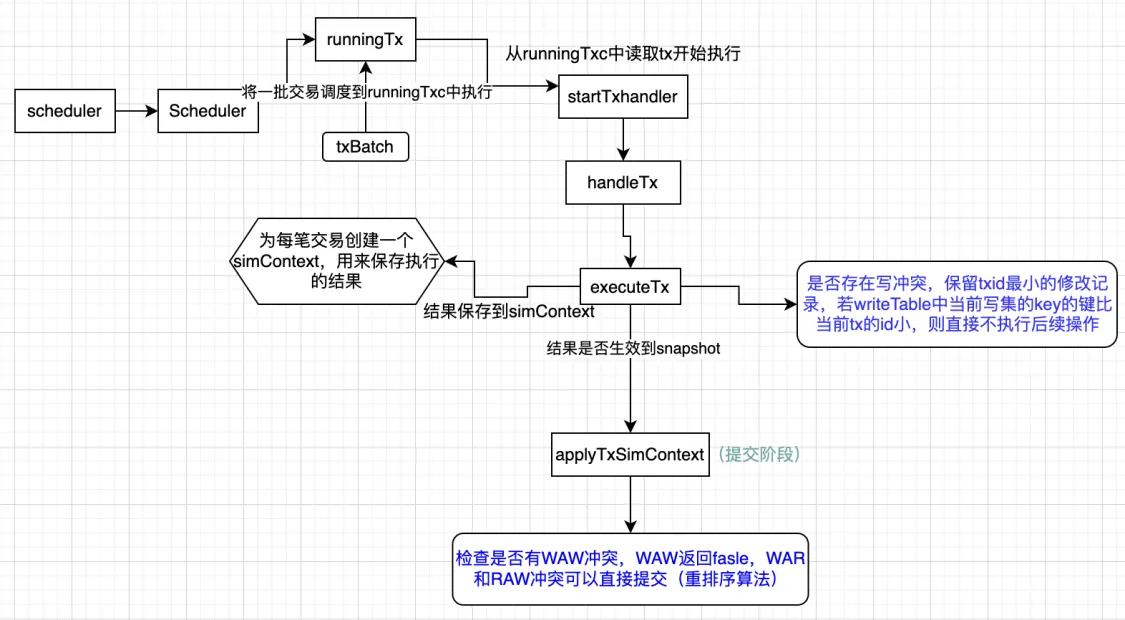
具体实现: snapshot_impl中实现了applyTxSimContext方法,也就是一笔交易tx执行完后,自己的上下文是否写入到snapshot中, 通过实现hasWAR和hasRAWConflict函数,返回是否存在这两种依赖,对WAW依赖直接在applyTxSimContext进行比较,WAR和RAW依赖,有一者不冲突即可提交交易
if !(hasWARConflicts(txExecSeq, txRWSet, s.readTable) == false ||
hasRAWConflicts(txExecSeq, txRWSet, s.writeTable) == false) {
s.log.Debugf("has conflicts with RAW or WAR, not install")
return false, len(s.txTable) + len(s.specialTxTable)
}
并打印日志,表示两者冲突都存在,不能将执行结果写入snapshot hasConflict方法: 拿到读写集和写表WriteTable和读表ReadTable进行比较,比较读写集中的key是否在Table中出现,并且比较seq的大小 算法主要的内容是只保留执行id小的交易 WAW冲突不在这里展示
// 检查是否有WAR冲突
func hasWARConflicts(txExecSeq int, TxRWSet *commonPb.TxRWSet, reservations *ShardSet) bool {
for _, txWrite := range TxRWSet.TxWrites {
key := constructKey(txWrite.ContractName, txWrite.Key)
if sv, ok := reservations.getByLock(key); ok && sv.seq < txExecSeq {
return true
}
}
return false
}
// 检查是否有RAW冲突
func hasRAWConflicts(txExecSeq int, TxRWSet *commonPb.TxRWSet, reservations *ShardSet) bool {
for _, txRead := range TxRWSet.TxReads {
key := constructKey(txRead.ContractName, txRead.Key)
if sv, ok := reservations.getByLock(key); ok && sv.seq < txExecSeq {
return true
}
}
return false
}
返回false上下文的交易会重新进入runningTxC等待下一次执行,已在scheduler中实现 如果能成功提交交易结果,就将交易的写集写入最终的表里面
for _, txWrite := range txRWSet.TxWrites {
finalKey := constructKey(txWrite.ContractName, txWrite.Key)
//写写不冲突直接生效交易结果
s.log.Debugf("tx id:%s 生效", tx.Payload.TxId)
finalWriteKvs[finalKey] = &sv{
value: txWrite.Value,
}
}
最终会打印时间和交易成功执行的数量,通过数量与时间算吞吐量进行比较,通过时间计算是否有提升
1.4.4. 测试部分:
1.本地goland启动solo模式下单节点 2.更改gosdk证书配置 执行main函数